基本介紹
- 中文名:線性分類器
- 外文名:Linear classifier
- 目標:具有相似特徵的對象聚集
- 學科:人工智慧
定義,生成模型與判別模型,二次分類器,
定義
如果輸入的特徵向量是實數向量 ,則輸出的分數為:
,則輸出的分數為:

其中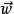 是一個權重向量,而f是一個函式,該函式可以通過預先定義的功能塊,映射兩個向量的點積,得到希望的輸出。權重向量
是一個權重向量,而f是一個函式,該函式可以通過預先定義的功能塊,映射兩個向量的點積,得到希望的輸出。權重向量 是從帶標籤的訓練樣本集合中所學到的。通常,"f"是個簡單函式,會將超過一定閾值的值對應到第一類,其它的值對應到第二類。一個比較複雜的"f"則可能將某個東西歸屬於某一類。
是從帶標籤的訓練樣本集合中所學到的。通常,"f"是個簡單函式,會將超過一定閾值的值對應到第一類,其它的值對應到第二類。一個比較複雜的"f"則可能將某個東西歸屬於某一類。
對於一個二元分類問題,可以構想成是將一個線性分類利用超平面劃分高維空間的情況: 在超平面一側的所有點都被分類成"是",另一側則分成"否"。
作為最快分類器,線性分類器通常套用於對分類速度有較高要求的情況下,特別是當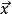 為稀疏向量時。雖然如此,決策樹可以更快。此外,當 的維度很大時,線形分類器通常表現良好。如文本分類時,傳統上, 中的一個元素是文章所使用到的某個辭彙的出現的次數。在這種情況下,分類器應被適當地正則化。
為稀疏向量時。雖然如此,決策樹可以更快。此外,當 的維度很大時,線形分類器通常表現良好。如文本分類時,傳統上, 中的一個元素是文章所使用到的某個辭彙的出現的次數。在這種情況下,分類器應被適當地正則化。
生成模型與判別模型
有兩種類型用來決定 的線性分類器。第一種模型條件機率 。這類的算法包括:
。這類的算法包括:
- 樸素貝葉斯分類器--- 假設為條件獨立性假設模型。
第二種方式則稱為判別模型(discriminative models),這種方法是試圖去最大化一個訓練集(training set)的輸出值。在訓練的成本函式中有一個額外的項加入,可以容易地表示正則化。例子包含:
- 感知元(Perceptron) --- 一個試圖去修正在訓練集中遇到錯誤的算法。
判別訓練通常會比模型化條件密度函式產生較高的準確。然而,在處理遺失資料時,使用條件密度模型通常是更為簡單的。
所有以上所列線性分類器算法,只要使用kernel trick都可被轉成在另一個向量空間的非線性算法。
二次分類器
統計分類考慮一個集合,每一個元素是一個對物件或事件觀察後所得的向量x,每一個都被分成y。 這個集合一般被稱為訓練資料。 問題是在於,要如何決定一個新的觀察項目其最好的類別應是哪一種。 對一個二次分類器,它假設其解會成二次關係,所以y是由以下來決定: