混沌系統是指在一個確定性系統中,存在著貌似隨機的不規則運動,其行為表現為不確定性、不可重複、不可預測,這就是混沌現象。混沌是非線性動力系統的固有特性,是非線性系統普遍存在的現象。按照動力學系統的性質,混沌可以分成四種類型:時間混沌、 空間混沌、時空混沌、功能混沌。較為典型的離散混沌系統有Logistic混沌系統。
基本介紹
- 中文名:離散混沌系統
- 外文名:Discrete chaotic system
- 學科:控制科學與工程
- 系統類別:非線性系統
- 基本釋義:離散的確定性和隨機性結合的系統
- 典型系統:Logistic映射混沌系統
概述,一維離散混沌系統,Logistic映射,Chebyshev映射,二維離散混沌系統,Lyapunov指數,形式,套用,
概述
混沌現象是在非線性動力系統中表現的確定性、類隨機的過程,這種過程既非周期又不收斂,並且對於初始值具有敏感的依賴性。
按照動力學系統的性質,混沌可以分成四種類型:
1)時間混沌;
2)空間混沌;
3)時空混沌;
4)功能混沌;
一維離散混沌系統
一個一維離散時間非線性動力學系統定義如下:

其中,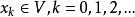 ,我們稱之為狀態。 而
,我們稱之為狀態。 而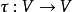 是一個映射,將當前狀態
是一個映射,將當前狀態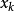 映射到下一個狀態
映射到下一個狀態 。如果我們從一個初始值
。如果我們從一個初始值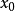 開始,反覆套用
開始,反覆套用 , 就得到一個序列
, 就得到一個序列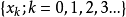 。這一序列稱為該離散時間動力系統的一條軌跡。
。這一序列稱為該離散時間動力系統的一條軌跡。
原始的蟲口模型方程是

體現了兩代蟲子的數量關係。將此方程推導一下,可以得到如下方程:
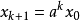
可以得到第n代蟲子和第0代蟲子的數量關係。
但是,從中不能表現自然的蟲子變換關係,因為蟲子的增長變化不是恆定的(考慮到很多負面影響,如蟲子太多時,由於食物有限和生存空間有限,還由於疾病等多種原因,使得蟲口數量減少),所以這個線性模型完全不能反映蟲口的變化規律。
Logistic映射
一類非常簡單卻被廣泛研究的動力系統是logistic映射,它起源於蟲口模型。其定義有多種形式。
形式一
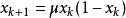
其中,混沌域為 ,
,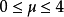 稱為分枝參數,
稱為分枝參數,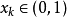 。混沌動力系統的研究工作指出,當
。混沌動力系統的研究工作指出,當 時,logistic映射工作於混沌態。也就是說,由初始條件
時,logistic映射工作於混沌態。也就是說,由初始條件 在logistic映射的作用下所產生的序列 是非周期的、不收斂的並對初始值非常敏感的。
在logistic映射的作用下所產生的序列 是非周期的、不收斂的並對初始值非常敏感的。
在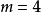 的情況下,即Logistic-Map映射,其所生成序列的機率密度函式PDF(probability density function):
的情況下,即Logistic-Map映射,其所生成序列的機率密度函式PDF(probability density function):

形式二

其中 ,混沌域為
,混沌域為 。當
。當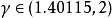 時,Logistic映射工作處於混沌狀態。當
時,Logistic映射工作處於混沌狀態。當 時,Logistic映射工作處於混沌狀態。
時,Logistic映射工作處於混沌狀態。
在 的滿射情況下,其所生成序列的機率密度函式PDF:
的滿射情況下,其所生成序列的機率密度函式PDF:

形式三

當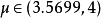 時,Logistic映射工作處於混沌狀態。在m接近4的範圍內生長的混沌序列的隨機性比較好。
時,Logistic映射工作處於混沌狀態。在m接近4的範圍內生長的混沌序列的隨機性比較好。
在 的滿射情況下,其所生成序列的機率密度函式PDF:
的滿射情況下,其所生成序列的機率密度函式PDF:
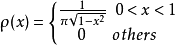
Chebyshev映射
Chebyshev 映射,以階數為參數。k 階Chebyshev 映射定義如下:

其中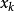 的定義區間是
的定義區間是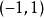 。
。
二維離散混沌系統
一維離散混沌系統,具有形式簡單、產生混沌序列時間短等優點,但其缺點是密鑰空間太小。用二維超混沌系統生成的混沌序列,變換成加密因子序列。
Lyapunov指數
Lyapunov指數(簡稱李氏指數),是刻畫非線性系統混沌特性的有效方法之一,李氏指數的個數與系統狀態空間的維數n相同。如果只有一個李氏指數大於零,則系統是混沌的;若至少有兩個李氏指數大於零,則系統是超混沌的。大於零的李氏指數越多,系統不穩定的程度越高。一般來說,系統的狀態量個數越多(如高維系統,對離散系統來說,n>2),它可能出現不穩定的程度越高。
形式
不失一般性,二維混沌離散系統有如下形式:
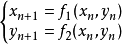
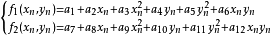
採用高維系統產生超混沌,由於系統比低維情況複雜,產生超混沌時序的時間增長,將有可能直接影響保密通訊實時性的要求。因此,如何在系統狀態變數個數儘可能少而正性李氏指數又儘可能多的條件下,尋找到非線性形式簡單的系統,是十分實際而又有意義的工作。為了尋找簡單形式餓二維離散超混沌系統,需要進一步簡化,使部分非線性項前面的係數為零,然後通過計算該系統的李氏指數,即有兩個或兩個以上大於零的李氏指數,可認為該系統是超混沌特性的二維離散系統。
下面是一些形式簡單且具有超混沌特性的二維離散系統,見下表:
 二維離散混沌系統
二維離散混沌系統套用
混沌套用可分為混沌綜合和混沌分析。前者利用人工產生的混沌從混沌動力學系統中獲得可能的功能,如人工神經網路的聯想記憶等;後者分析由複雜的人工和自然系統中獲得的混沌信號並尋找隱藏的確定性規則,如時間序列數據的非線性確定性預測等。
混沌的具體的潛在套用可概括如下:
(1)最佳化:利用混沌運動的隨機性、遍歷性和規律性尋找最優點,可用於系統辨識、最優參數設計等眾多方面。
(2)神經網路:將混沌與神經網路相融合,使神經網路由最初的混沌狀態逐漸退化到一般的神經網路,利用中間過程混沌狀態的動力學特性使神經網路逃離局部極小點,從而保證全局最優,可用於聯想記憶、機器人的路徑規劃等。
(3)圖像數據壓縮:把複雜的圖像數據用一組能產生混沌吸引子的簡單動力學方程代替,這樣只需記憶存儲這一組動力學方程組的參數,其數據量比原始圖像數據大大減少,從而實現了圖像數據壓縮。
(4)高速檢索:利用混沌的遍歷性可以進行檢索,即在改變初值的同時,將要檢索的數據和剛進入混沌狀態的值相比較,檢索出接近於待檢索數據的狀態。這種方法比隨機檢索或遺傳算法具有更高的檢索速度。
(5)非線性時間序列的預測:任何一個時間序列都可以看成是一個由非線性機制確定的輸入輸出系統,如果不規則的運動現象是一種混沌現象,則通過利用混沌現象的決策論非線性技術就能高精度地進行短期預測。
(6)模式識別:利用混沌軌跡對初始條件的敏感性,有可能使系統識別出只有微小區別的不同模式。
(7)故障診斷:根據由時間序列再構成的吸引子的集合特徵和採樣時間序列數據相比較,可以進行故障診斷。
