
基本介紹
- 中文名:貝葉斯線性回歸
- 外文名:Bayesian linear regression
- 類型:回歸算法
- 提出者:Dennis Lindley,Adrian Smith
- 提出時間:1972年
- 學科:統計學
歷史,理論與算法,模型,求解,預測,性質,套用,
歷史
貝葉斯線性回歸是二十世紀60-70年代貝葉斯理論興起時得到發展的統計方法之一,其早期工作包括在回歸模型中對權重先驗和最大後驗密度(Highest Posterior Density, HPD)的研究、在貝葉斯視角下發展的隨機效應模型(random effect mode)以及貝葉斯統計中可交換性(exchangeability)概念的引入。
正式提出貝葉斯回歸方法的工作來自英國統計學家Dennis Lindley和Adrian Smith,在其1972年發表的兩篇論文中,Lindley和Smith對貝葉斯線性回歸進行了系統論述並通過數值試驗與其它線性回歸方法進行了比較,為貝葉斯線性回歸的套用奠定了基礎。
理論與算法
模型
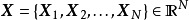
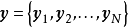

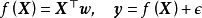



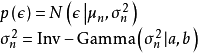


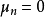
求解

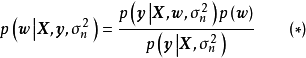
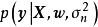
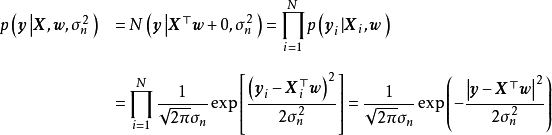
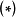
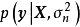

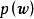
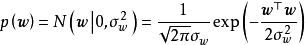
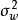
先驗、似然和後驗,(b)回歸結果") 一維貝葉斯線性回歸:(a,c,d)先驗、似然和後驗,(b)回歸結果
一維貝葉斯線性回歸:(a,c,d)先驗、似然和後驗,(b)回歸結果在權重係數沒有合理先驗假設的問題中,貝葉斯線性回歸可使用無信息先驗(uninformative prior),即一個均勻分布(uniform distribution),此時權重係數按均等的機會取任意值。
極大後驗估計(Maximum A Posteriori estimation, MAP)
在貝葉斯線性回歸中,MAP可以被視為一種特殊的貝葉斯估計(Bayesian estimator),其求解步驟與極大似然估計(maximum likelihood estimation)類似。對給定的先驗,MAP將 式轉化為求解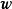 使後驗機率最大的最佳化問題,並求得後驗的眾數(mode)。由於常態分配的眾數即是均值,因此MAP通常被套用於正態先驗。
使後驗機率最大的最佳化問題,並求得後驗的眾數(mode)。由於常態分配的眾數即是均值,因此MAP通常被套用於正態先驗。
這裡以的0均值正態先驗為例介紹MAP的求解步驟,首先給定權重係數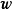 的0均值常態分配先驗:
的0均值常態分配先驗: 。由於邊緣似然與
。由於邊緣似然與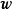 相互獨立,此時求解後驗機率的極大值等價於求解似然和先驗乘積的極大值:
相互獨立,此時求解後驗機率的極大值等價於求解似然和先驗乘積的極大值:
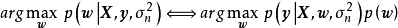
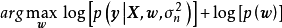
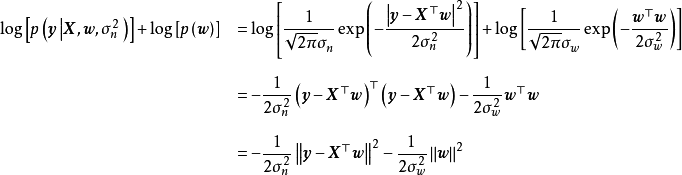



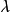
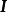
除正態先驗外,MAP也使用拉普拉斯分布(Laplace distribution)作為權重係數的先驗:
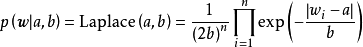

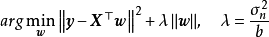
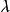
MAP是單點估計,不支持線上學習(online learning),也無法提供置信區間,但能夠以很小的計算量求解貝葉斯線性回歸的權重係數,且可用於最常見的正態先驗情形。使用正態先驗和MAP求解的貝葉斯線性回歸等價於嶺回歸(ridge regression),最佳化目標中的 被稱為L2正則化項;使用拉普拉斯分布先驗的情形對應線性模型的LASSO(Least Absolute Shrinkage and Selection Operator),
被稱為L2正則化項;使用拉普拉斯分布先驗的情形對應線性模型的LASSO(Least Absolute Shrinkage and Selection Operator),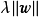 被稱為L1正則化項。
被稱為L1正則化項。
共軛先驗求解
由於貝葉斯線性回歸的似然是常態分配,因此在權重係數的先驗存在共軛分布時可利用共軛性(conjugacy)求解後驗。這裡以正態先驗為例介紹其求解步驟。
首先引入權重係數的0均值正態先驗: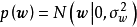 ,隨後由 式可知,後驗正比於似然和先驗的乘積:
,隨後由 式可知,後驗正比於似然和先驗的乘積:

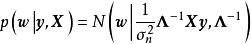
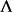
數值方法
一般地,貝葉斯推斷的數值方法都適用於貝葉斯線性回歸,其中最常見的是馬爾可夫鏈蒙特卡羅(Markov Chain Monte Carlo, MCMC)。這裡以MCMC中的吉布斯採樣(Gibbs sampling)算法為例介紹。
給定均值為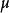 ,方差為
,方差為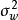 的正態先驗
的正態先驗 和權重係數
和權重係數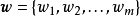 ,吉布斯採樣是一個疊代算法,每個疊代都依次採樣所有的權重係數:
,吉布斯採樣是一個疊代算法,每個疊代都依次採樣所有的權重係數:
1. 隨機初始化權重係數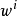 和殘差的方差
和殘差的方差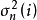
2. 採樣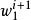 :
:
3. 使用 採樣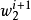 :
: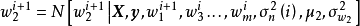
4. 採樣 :
:
5. 重複1-4至疊代完成/分布收斂
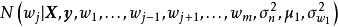
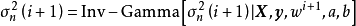
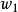

在Python 3的Numpy模組下,上述疊代步驟可有如下編程實現:
import numpy as npimport matplotlib.pyplot as plt# 構建測試數據## 自變數:[0,5]區間均勻分布x = np.random.uniform(low=0, high=5, size=5)## 因變數:y=2x-1+eps, eps=norm(0, 0.5)y = np.random.normal(2*x-1, 0.5)def calculate_csd(x, y, w1, w2, s, N, hyper_param): ''' 條件採樣分布函式: (w1, w2, s) x , y: 輸入數據 w1, w2: 線性回歸模型的截距和斜率 s: 殘差方差 N: 樣本量 ''' # 超參數 mu1, s1 = hyper_param["mu1"], hyper_param['s1'] mu2, s2 = hyper_param["mu2"], hyper_param['s2'] a, b, = hyper_param["a"], hyper_param["b"] # 計算方差 var1 = (s1*s)/(s+s1*N) var2 = (s*s2)/(s+s2*np.sum(x*x)) # 計算均值 mean1 = (s*mu1+s1*np.sum(y-w2*x))/(s+s1*N) mean2 = (s*mu2+s2*np.sum((y-w1)*x))/(s+s2*np.sum(x*x)) # 計算(a, b) eps = y-w1-w2*x a = a+N/2; b = b+np.sum(eps*eps)/2 # 使用numpy.random採樣(inv-gamma=1/gamma) # 注意numpy.random中normal和gamma的定義方式: ## np.random.normal(mean, std) ## inv-Gamma = 1/np.random.gamma(a, scale), scale=1/b return np.random.normal(mean1, np.sqrt(var1)), \ np.random.normal(mean2, np.sqrt(var2)), \ 1/np.random.gamma(a, 1/b)def Gibbs_sampling(x, y, iters, init, hyper_param): ''' 吉布斯採樣算法主程式 iter: 疊代次數 init: 初始值 hyper_param: 超參數 ''' N = len(y) # 樣本量 # 採樣初始值 w1, w2, s = init["w1"], init["w2"], init["s"] # 使用數組記錄疊代值 history = np.zeros([iters, 3])*np.nan # for循環疊代 for i in range(iters): w1, w2, s = calculate_csd(x, y, w1, w2, s, N, hyper_param) history[i, :] = np.array([w1, w2, s]) return history# 開始採樣iters = 10000 # MCMC疊代1e4次init = {'w1': 0, 'w2': 0, 's': 0}hyper_param = {'mu1': 0, 's1': 1, 'mu2': 0, 's2': 1, 'a': 2, 'b': 1}history = Gibbs_sampling(x, y, iters, init, hyper_param)burnt = history[500:] # 截取收斂後的馬爾可夫鏈ax1 = plt.subplot(2, 1, 1); ax2 = plt.subplot(2, 1, 2)ax1.hist(burnt[:, 0], bins=100)ax1.text(2, 0.025*iters, '$\mathrm{N(w_1|\mu,s)}$', fontsize=14)ax2.hist(burnt[:, 1], bins=100)ax2.text(.5, 0.025*iters, '$\mathrm{N(w_2|\mu,s)}$', fontsize=14)除吉布斯採樣外,Metropolis-Hastings算法和數據增強算法(data augmentation algorithm)也可用於貝葉斯線性回歸的MCMC計算。
預測
由MAP求解的貝葉斯線性回歸可直接使用權重係數對預測數據進行計算。MAP是單點估計,因此預測結果不提供後驗分布。對共軛先驗或數值方法求解的貝葉斯線性回歸,可通過邊緣化(marginalized out)模型權重,即按其後驗積分得到預測結果:
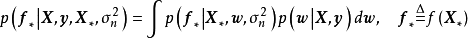
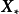

模型驗證
邊緣似然描述了似然和先驗的組合在多大程度上解釋了觀測數據,因此邊緣似然可以用於計算貝葉斯因子,與其它模型進行比較並驗證模型和先驗的合理性。由全機率公式(law of total probability)可知,邊緣似然有如下積分形式:

由MCMC計算的貝葉斯線性回歸也可以使用數值方法進行交叉驗證(cross-validation),具體方法包括重採樣(re-sampling MCMC)和使用EC(Expectation Consistent)近似的留一法(Leave One Out, LOO)交叉驗證。
線上學習
由共軛先驗和數值方法求解的貝葉斯線性回歸可以進行線上學習,即使用實時數據對權重係數進行更新。線上學習的具體方法依模型本身而定,其設計思路是將先錢求解得到的後驗作為新的先驗,並帶入數據得到後驗。
性質
穩健性:由求解部分的推導可知,若貝葉斯線性回歸使用正態先驗,則其MAP的估計結果等價於嶺回歸,而使用拉普拉斯先驗的情形對應線性模型的LASSO,因此貝葉斯線性回歸與使用正則化(regularization)的回歸分析一樣平衡了模型的經驗風險和結構風險。特別地,使用拉普拉斯先驗的貝葉斯線性回歸由於可以得到稀疏解,因此具有一定的變數篩選(variable selection)能力。
作為貝葉斯推斷所具有的性質:由於貝葉斯線性回歸是貝葉斯推斷線上性回歸問題中的套用,因此其具有貝葉斯方法的一般性質,包括對先驗進行實時更新、將觀測數據視為定點因而不需要漸進假設、服從似然定理(likelihood principle)、估計結果包含置信區間等。基於最小二乘法的線性回歸(Ordinary Linear Regression, OLR)通常僅在觀測數據顯著地多於權重係數維數的時候才會有好的效果,而貝葉斯線性回歸沒有此類限制,且在權重係數維數過高是,可以根據後驗對模型進行降維(dimensionality reduction)。
與高斯過程回歸(Gaussian Process Regression, GPR)的比較:貝葉斯線性回歸是GPR在權重空間(weight-space)下的特例。在貝葉斯線性回歸中引入映射函式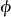 可得到GPR的預測形式:
可得到GPR的預測形式: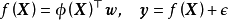 ,而當映射函式為等值函式(identity function)時,GPR退化為貝葉斯線性回歸。
,而當映射函式為等值函式(identity function)時,GPR退化為貝葉斯線性回歸。
