
基本介紹
- 中文名:多重線性回歸
- 外文名:multiple linear regression
- 簡稱:多重回歸
- 所屬學科:數學
- 相關概念:偏回歸係數,殘差,多重共線性等
基本信息,參數估計,假設檢驗,自變數的選擇,解決方案,
基本信息
多重線性回歸的數學模型為:










由樣本估計的多重線性回歸方程為:




不能直接用各自變數的普通偏回歸係數的數值大小來比較方程中它們對因變數y的貢獻大小,因為p個自變數的計量單位及變異度不同。可將原始數據進行標準化,即

然後用標準化的數據進行回歸模型擬合,此時獲得的回歸係數記為 ,稱為標準化偏回歸係數(standardized partial regression coefficient ),又稱為通徑係數(pathcoefficient)。標準化偏回歸係數
,稱為標準化偏回歸係數(standardized partial regression coefficient ),又稱為通徑係數(pathcoefficient)。標準化偏回歸係數 絕對值較大的自變數對因變數y的貢獻大。
絕對值較大的自變數對因變數y的貢獻大。
參數估計
多重線性回歸分析中回歸係數的估計也是通過最小二乘法(method of least square),即尋找適宜的係數 使得因變數殘差平方和達到最小。其基本原理是: 利用觀察或收集到的因變數和自變數的一組數據建立一個線性函式模型,使得這個模型的理論值與觀察值之間的離均差平方和最小。
使得因變數殘差平方和達到最小。其基本原理是: 利用觀察或收集到的因變數和自變數的一組數據建立一個線性函式模型,使得這個模型的理論值與觀察值之間的離均差平方和最小。
假設檢驗
建立的回歸方程是否符合資料特點,以及能否恰當地反映因變數y與p個自變數的數量依存關係,就必須對該模型進行檢驗。
1.回歸方程的檢驗與評價。無效假設 ;備擇假設
;備擇假設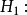 各
各 不全為0。檢驗統計量為F,計算公式為:
不全為0。檢驗統計量為F,計算公式為:



2.自變數的假設檢驗。
(1) 偏回歸平方和檢驗。回歸方程中某一自變數 的偏回歸平方和(sum of squaresfor partial regression),表示從模型中剔除後引起的回歸平方和的減少量。偏回歸平方和用SS回歸
的偏回歸平方和(sum of squaresfor partial regression),表示從模型中剔除後引起的回歸平方和的減少量。偏回歸平方和用SS回歸 表示,其大小說明相應自變數的重要性。
表示,其大小說明相應自變數的重要性。
檢驗統計量F的計算公式為:

(2) 偏回歸係數的 檢驗。偏回歸係數的t檢驗是在回歸方程具有統計學意義的情況下,檢驗某個總體偏回歸係數是否等於0的假設檢驗,以判斷相應的自變數是否對因變數y的變異確有貢獻。
檢驗。偏回歸係數的t檢驗是在回歸方程具有統計學意義的情況下,檢驗某個總體偏回歸係數是否等於0的假設檢驗,以判斷相應的自變數是否對因變數y的變異確有貢獻。

檢驗統計量t的計算公式為:



自變數的選擇
在許多多重線性回歸中,模型中包含的自變數沒有辦法事先確定,如果把一些不重要的或者對因變數影響很弱的變數引人模型,則會降低模型的精度。所以自變數的選擇是必要的,其基本思路是: 儘可能將對因變數影響大的自變數選入回歸方程中,並儘可能將對因變數影響小的自變數排除在外,即建立所謂的“最優”方程。
1.篩選標準與原則。對於自變數各種不同組合建立的回歸模型,使用全局擇優法選擇“最優”的回歸模型。
(1) 殘差平方和縮小與決定係數增大。如果引人一個自變數後模型的殘差平方和減少很多,那么說明該自變數對因變數y貢獻大,將其引入模型;反之,說明該自變數對因變數y貢獻小,不應將其引入模型。另一方面,如果某一變數剔除後模型的殘差平方和增加很多,則說明該自變數對因變數y貢獻大,不應被剔除;反之,說明該自變數對因變數y貢獻小,應被剔除。決定係數增大與殘差平方和縮小完全等價。
(2) 殘差均方縮小與調整決定係數增大。殘差均方縮小的準則是在殘差平方和縮小準則基礎上增加了 因子,它隨模型中自變數p的增加而增加,體現出對模型中自變數個數增加所實施的懲罰。調整決定係數增大與殘差均方縮小完全等價。
因子,它隨模型中自變數p的增加而增加,體現出對模型中自變數個數增加所實施的懲罰。調整決定係數增大與殘差均方縮小完全等價。
(3)  統計量。由C.L.Mallows提出,其定義為:
統計量。由C.L.Mallows提出,其定義為:

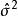

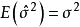




2.自變數篩選常用方法。常用方法如下:
(1) 前進法(forward selection)。事先定一個選人自變數的標準。開始時,方程中只含常數項,按自變數對y的貢獻大小由大到小依次選入方程。每選入一個自變數,則要重新計算方程外各自變數(剔除已選人變數的影響後) 對y的貢獻,直到方程外變數均達不到選入標準為止。變數一旦進人模型,就不會被剔除。
(2) 後退法(backward selection)。事先定一個剔除自變數的標準。開始時,方程中包含全部自變數,按自變數y對的貢獻大小由小到大依次剔除。每剔除一個變數,則重新計算未被剔除的各變數對y的貢獻大小,直到方程中所有變數均不符合剔除標準,沒有變數可被剔除為止。自變數一旦被剔除,則不考慮進入模型。
(3) 逐步回歸法(stepwise selection)。本法區別於前進法的根本之處是每引人一個自變數,都會對已在方程中的變數進行檢驗,對符合剔除標準的變數要逐一剔除。
解決方案
多重共線性(multi-colinearity) 是進行多重回歸分析時存在的一個普遍問題。多重共線性是指自變數之間存在近似的線性關係,即某個自變數能近似地用其他自變數的線性函式來表示。在實際回歸分析套用中,自變數間完全獨立很難,所以共線性的問題並不少見。自變數一般程度上的相關不會對回歸結果造成嚴重的影響,然而,當共線性趨勢非常明顯時,它就會對模型的擬合帶來嚴重影響。
(1) 偏回歸係數的估計值大小甚至是方向明顯與常識不相符。
(2) 從專業角度看對因變數有影響的因素,卻不能選入方程中。
(3) 去掉一兩個記錄或變數,方程的回歸係數值發生劇烈的變化,非常不穩定。
(4) 整個模型的檢驗有統計學意義,而模型包含的所有自變數均無統計學意義。
當出現以上情況時,就需要考慮是不是變數之間存在多重共線性。
多重共線性的診斷
在做多重回歸分析的共線性診斷時,首先要對所有變數進行標準化處理。SPSS中可以通過以下指標來輔助判斷有無多重共線性存在。
(1) 相關係數。通過做自變數間的散點圖觀察或者計算相關係數判斷,看是否有一些自變數間的相關係數很高。一般來說,2個自變數的相關係數超過0.9,對模型的影響很大,將會出現共線性引起的問題。這只能做初步的判斷,並不全面。
(2) 容忍度(tolerance)。以每個自變數作為因變數對其他自變數進行回歸分析時得到的殘差比例,大小用1減去決定係數來表示。該指標值越小,則說明被其他自變數預測的精度越高,共線性可能越嚴重。
(3) 方差膨脹因子(variance inflation factor,VIF)。方差膨脹因子是容忍度的倒數,VIF越大,顯示共線性越嚴重。VIF>10時,提示有嚴重的多重共線性存在。
(4) 特徵根(eigenvalue)。實際上是對自變數進行主成分分析,如果特徵根為0,則提示有嚴重的共線性。
(5) 條件指數(condition index)。當某些維度的該指標大於30時,則提示存在共線性。
共線性解決方案
自變數間確實存在多重共線性,直接採用多重回歸得到的模型肯定是不可信的,此時可以用下面的辦法解決。
(1) 增大樣本含量,能部分解決多重共線性問題。
(2) 把多種自變數篩選的方法結合起來擬合模型。建立一個“最優”的逐步回歸方程,但同時丟失一部分可利用的信息。
(3) 從專業知識出發進行判斷,去除專業上認為次要的,或者是缺失值比較多、測量誤差較大的共線性因子。
(4) 進行主成分分析,提取公因子代替原變數進行回歸分析。
(5) 進行嶺回歸分析,可以有效解決多重共線性問題。
(6) 進行通徑分析(path analysis),可以對應自變數間的複雜關係精細刻畫。
