
如果一個估計問題所涉及的分布未知或不能用有窮參數來刻劃,稱這種估計為非參數估計。一般由樣本估計未知分布函式或未知機率密度,由樣本估計某一對稱分布的分布中心都是非參數估計。常被套用於測驗分數統計中。
基本介紹
- 中文名:非參數估計
- 外文名:nonparametric estimation
- 所屬學科:數學(統計學)
- 簡介:一類估計方法
基本介紹,相關介紹,
基本介紹
非參數估計(nonparametric estimation)是相對於參數估計來說的一類估計方法。 在非參數估計中,對基本分布不做假定,主要利用隨機抽樣本身的信息來對估計量的優劣作出判斷,最大得分估計量方法就是一種非參數估計方法;而在參數估計中,對基本分布先要做出假定,只是其特徵值需要估計,如在古典假設中常常假定隨機擾動項U服從常態分配,特徵值μ和方差σ待定。非參數回歸與非參數估計相近,非參數回歸函式形式不確定,其結果外延困難,但擬合效果卻比較好。非參數回歸的基本方法有核函式法,最近鄰函式法,樣條函式法,小波函式法。這些方法儘管起源不一樣,數學形式相距甚遠,但都可以視為關於Yi的線性組合的某種權函式。也就是說,回歸函式g(X)的估計gn(X)總可以表為下述形式:
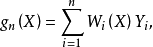
在一般實際問題中,權函式都滿足下述條件:

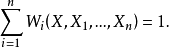
相關介紹
非參數估計又稱為非參數檢驗,是指在不考慮原總體分布或者不作關於參數假定的前提下,直接用已知類別的學習樣本的先驗知識直接進行統計檢驗和判斷分析的一系列方法的總稱。
非參數估計不假定數學模型,可避免對總體分布的假定不當導致重大錯誤所以常有較好的穩健性(見“穩健統計”)。而參數估計要求函式的數學模型形式已知,如假定研究的問題具有常態分配或二項分布,再用已知類別的學習樣本估計裡面的參數,但這種假定有時並不成立。
由於非參數統計中對分布假定要求的條件寬,因而大樣本理論(見大樣本統計)占據了主導地位。第二次世界大戰前,非參數統計的大樣本理論已有了一些結果,從20世紀50年代至今,更是有了顯著的進展,尤其是關於秩統計量與U統計量的大樣本理論,以及基於這種理論的大樣本非參數方法,研究成果很多。近代理論證明了一些重要的非參數統計方法,當與相應的參數方法比較時,即使在最有利於後者的情況下,效率上的損失也很小。
非參數估計主要適用於以下方面:
(1)待分析數據不滿足參數檢驗的假設條件時。
(2)客觀對象採用名義尺度或順序尺度度量時應當使用非參數估計。當客觀對象採用名義尺度或者順序尺度時,如消費者對不同商標的飲料的喜惡程度,傳統的參數方法無法對其進行檢驗,因此應當使用非參數估計。
優點:①假設條件少,套用範圍廣泛;②運算簡單,可節省運算時間;③方法直觀,不需要太多的數學基礎知識和統計學知識,容易理解;④能夠適應名義尺度和順序尺度等對象,而參數估計不行;⑤當推論多達三個以上時,非參數統計方法尤其具有優越性。
缺點:①方法簡單,檢驗功效差,即在給定的顯著性水平下進行檢驗時,非參數統計方法與參數統計方法相比,第Ⅱ類錯誤的機率β要大些;②對於大樣本,如不採用適當的近似,計算可能變得十分複雜。
因此,總體來說非參數估計適用於估計隱含影響因素較多的權證隱含波動率,而且使用Matlab軟體作非參數估計,可以很好地克服計算工作量大的缺點。
