卷積神經網路中每層卷積層(Convolutional layer)由若干卷積單元組成,每個卷積單元的參數都是通過反向傳播算法最佳化得到的。卷積運算的目的是提取輸入的不同特徵,第一層卷積層可能只能提取一些低級的特徵如邊緣、線條和角等層級,更多層的網路能從低級特徵中疊代提取更複雜的特徵。
基本介紹
- 中文名:卷積層
- 外文名:Convolutional layer
- 領域:人工智慧
卷積神經網路,卷積神經網路結構,卷積層,線性整流層,池化層(Pooling Layer),損失函式層,卷積神經網路的套用,影像辨識,自然語言處理,藥物發現,圍棋,可用包,
卷積神經網路
卷積神經網路(Convolutional Neural Network,CNN)是一種前饋神經網路,它的人工神經元可以回響一部分覆蓋範圍內的周圍單元,對於大型圖像處理有出色表現。
卷積神經網路由一個或多個卷積層和頂端的全連通層(對應經典的神經網路)組成,同時也包括關聯權重和池化層(pooling layer)。這一結構使得卷積神經網路能夠利用輸入數據的二維結構。與其他深度學習結構相比,卷積神經網路在圖像和語音識別方面能夠給出更好的結果。這一模型也可以使用反向傳播算法進行訓練。相比較其他深度、前饋神經網路,卷積神經網路需要考量的參數更少,使之成為一種頗具吸引力的深度學習結構。
卷積神經網路結構
卷積層
卷積層(Convolutional layer),卷積神經網路中每層卷積層由若干卷積單元組成,每個卷積單元的參數都是通過反向傳播算法最佳化得到的。卷積運算的目的是提取輸入的不同特徵,第一層卷積層可能只能提取一些低級的特徵如邊緣、線條和角等層級,更多層的網路能從低級特徵中疊代提取更複雜的特徵。
線性整流層
線性整流層(Rectified Linear Units layer, ReLU layer)使用線性整流(Rectified Linear Units, ReLU) 作為這一層神經的激勵函式(Activation function)。它可以增強判定函式和整個神經網路的非線性特性,而本身並不會改變卷積層。
作為這一層神經的激勵函式(Activation function)。它可以增強判定函式和整個神經網路的非線性特性,而本身並不會改變卷積層。
事實上,其他的一些函式也可以用於增強網路的非線性特性,如雙曲正切函式 ,
,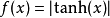 ,或者Sigmoid函式
,或者Sigmoid函式 。相比其它函式來說,ReLU函式更受青睞,這是因為它可以將神經網路的訓練速度提升數倍,而並不會對模型的泛化準確度造成顯著影響。
。相比其它函式來說,ReLU函式更受青睞,這是因為它可以將神經網路的訓練速度提升數倍,而並不會對模型的泛化準確度造成顯著影響。
池化層(Pooling Layer)
池化(Pooling)是卷積神經網路中另一個重要的概念,它實際上是一種形式的降採樣。有多種不同形式的非線性池化函式,而其中“最大池化(Max pooling)”是最為常見的。它是將輸入的圖像劃分為若干個矩形區域,對每個子區域輸出最大值。直覺上,這種機制能夠有效地原因在於,在發現一個特徵之後,它的精確位置遠不及它和其他特徵的相對位置的關係重要。池化層會不斷地減小數據的空間大小,因此參數的數量和計算量也會下降,這在一定程度上也控制了過擬合。通常來說,CNN的卷積層之間都會周期性地插入池化層。
池化層通常會分別作用於每個輸入的特徵並減小其大小。目前最常用形式的池化層是每隔2個元素從圖像劃分出 的區塊,然後對每個區塊中的4個數取最大值。這將會減少75%的數據量。
的區塊,然後對每個區塊中的4個數取最大值。這將會減少75%的數據量。
除了最大池化之外,池化層也可以使用其他池化函式,例如“平均池化”甚至“L2-範數池化”等。過去,平均池化的使用曾經較為廣泛,但是最近由於最大池化在實踐中的表現更好,平均池化已經不太常用。
由於池化層過快地減少了數據的大小,目前文獻中的趨勢是使用較小的池化濾鏡,甚至不再使用池化層。
損失函式層
損失函式層(loss layer)用於決定訓練過程如何來“懲罰”網路的預測結果和真實結果之間的差異,它通常是網路的最後一層。各種不同的損失函式適用於不同類型的任務。例如,Softmax交叉熵損失函式常常被用於在K個類別中選出一個,而Sigmoid交叉熵損失函式常常用於多個獨立的二分類問題。歐幾里德損失函式常常用於結果取值範圍為任意實數的問題。
卷積神經網路的套用
影像辨識
卷積神經網路通常在圖像分析(image analysis)和圖像處理(image processing)領域中使用。關係密切,兩者有一定程度的交叉,但是又有所不同。圖像處理側重於信號處理方面的研究,比如圖像對比度的調節、圖像編碼、去噪以及各種濾波的研究。但是圖像分析更側重點在於研究圖像的內容,包括但不局限於使用圖像處理的各種技術,它更傾向於對圖像內容的分析、解釋、和識別。因而,圖像分析和計算機科學領域中的模式識別、計算機視覺關係更密切一些。
圖像分析一般利用數學模型並結合圖像處理的技術來分析底層特徵和上層結構,從而提取具有一定智慧型性的信息。
圖像分析研究的領域一般包括:
- 基於內容的圖像檢索(CBIR-Content Based Image Retrieval)
- 人臉識別(face recognition)
- 表情識別(emotion recognition)
- 光學字元識別(OCR-Optical Character Recognition)
- 手寫體識別(handwriting recognition)
- 醫學圖像分析(biomedical image analysis)
- 視頻對象提取(video object extraction)
自然語言處理
卷積神經網路也常被用於自然語言處理。 CNN的模型被證明可以有效的處理各種自然語言處理的問題,如語義分析、搜尋結果提取、句子建模、分類、預測、和其他傳統的NLP任務等。
自然語言處理(英語:natural language processing,縮寫作NLP)是人工智慧和語言學領域的分支學科。此領域探討如何處理及運用自然語言;自然語言認知則是指讓電腦“懂”人類的語言。
自然語言生成系統把計算機數據轉化為自然語言。自然語言理解系統把自然語言轉化為電腦程式更易於處理的形式。
自然語言處理研究的領域一般包括:
給一句人類語言的問句,決定其答案。 典型問題有特定答案 (像是加拿大的首都叫什麼?),但也考慮些開放式問句(像是人生的意義是是什麼?)
- 機器翻譯(Machine translation)
將某種人類語言自動翻譯至另一種語言
- 自動摘要(Automatic summarization)
產生一段文字的大意,通常用於提供已知領域的文章摘要,例如產生報紙上某篇文章之摘要
- 文字蘊涵(Textual entailment)
藥物發現
卷積神經網路已在藥物發現中使用。卷積神經網路被用來預測的分子與蛋白質之間的相互作用,以此來尋找靶向位點,尋找出更可能安全和有效的潛在治療方法。
圍棋
參見:AlphaGo李世乭五番棋
可用包
- Torch7(www.torch.ch)
- OverFeat
- Cuda-convnet
- MatConvnet
- Theano:用Python實現的神經網路包
- Paddlepaddle
