
基本介紹
- 中文名:K平均算法
- 外文名:k-means algorithm
- 處理:與最大期望算法很相似
- 發明於:1956年
簡介,算法描述,歷史源流,
簡介
k-平均算法(英文:k-means clustering)源於信號處理中的一種向量量化方法,現在則更多地作為一種聚類分析方法流行於數據挖掘領域。k-平均聚類的目的是:把{\displaystyle n}個點(可以是樣本的一次觀察或一個實例)劃分到k個聚類中,使得每個點都屬於離他最近的均值(此即聚類中心)對應的聚類,以之作為聚類的標準。這個問題將歸結為一個把數據空間劃分為Voronoi cells的問題。
這個問題在計算上是NP困難的,不過存在高效的啟發式算法。一般情況下,都使用效率比較高的啟發式算法,它們能夠快速收斂於一個局部最優解。這些算法通常類似於通過疊代最佳化方法處理高斯混合分布的最大期望算法(EM算法)。而且,它們都使用聚類中心來為數據建模;然而k-平均聚類傾向於在可比較的空間範圍內尋找聚類,期望-最大化技術卻允許聚類有不同的形狀。
k-平均聚類與k-近鄰之間沒有任何關係(後者是另一流行的機器學習技術)。
算法描述
已知觀測集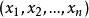 ,其中每個觀測都是一個{\displaystyle d}-維實向量,k-平均聚類要把這n個觀測劃分到k個集合中(k≤n),使得組內平方和(WCSS within-cluster sum of squares)最小。換句話說,它的目標是找到使得下式滿足的聚類
,其中每個觀測都是一個{\displaystyle d}-維實向量,k-平均聚類要把這n個觀測劃分到k個集合中(k≤n),使得組內平方和(WCSS within-cluster sum of squares)最小。換句話說,它的目標是找到使得下式滿足的聚類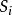 ,
,
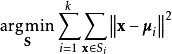
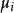
歷史源流
雖然其思想能夠追溯到1957年的Hugo Steinhaus,術語“k-均值”於1967年才被James MacQueen首次使用。標準算法則是在1957年被Stuart Lloyd作為一種脈衝碼調製的技術所提出,但直到1982年才被貝爾實驗室公開出版。在1965年,E.W.Forgy發表了本質上相同的方法,所以這一算法有時被稱為Lloyd-Forgy方法。更高效的版本則被Hartigan and Wong提出(1975/1979)。
