
逼近理論是將如何將一函式用較簡單的函式來找到最佳逼近,且所產生的誤差可以有量化的表征。
基本介紹
- 中文名:逼近理論
- 外文名:approximation theory
- 領域:數學
- 套用:數值分析
概念,分類,1.最佳多項式,2.切比雪夫近似,3.雷米茲算法,
概念
逼近理論是將如何將一函式用較簡單的函式來找到最佳逼近,且所產生的誤差可以有量化的表征,以上提及的“最佳”及“較簡單”的實際意義都會隨著套用而不同。
數學中有一個相關性很高的主題,是用廣義傅立葉級數進行函式逼近,也就是用以正交多項式為基礎的級數來進行逼近。
計算機科學中有一個問題和逼近理論有關,就是在數學函式庫中如何用計算機或計算器可以執行的功能(例如乘法和加法)儘可能的逼近某一數學函式,一般會用多項式或有理函式(二多項式的商)來進行。
逼近理論的目標是儘可能的逼近實際的函式,一般精度會接近電腦浮點運算的精度,一般會用高次的多項式,以及(或者)縮小多項式逼近函式的區間。縮小區間可以針對要逼近的函式,利用許多不同的係數及增益來達到。現在的數學函式庫會將區間劃分為許多的小區間,每個區間搭配一個次數不高的多項式。
數學中有一個相關性很高的主題,是用廣義傅立葉級數進行函式逼近,也就是用以正交多項式為基礎的級數來進行逼近。
計算機科學中有一個問題和逼近理論有關,就是在數學函式庫中如何用計算機或計算器可以執行的功能(例如乘法和加法)儘可能的逼近某一數學函式,一般會用多項式或有理函式(二多項式的商)來進行。
逼近理論的目標是儘可能的逼近實際的函式,一般精度會接近電腦浮點運算的精度,一般會用高次的多項式,以及(或者)縮小多項式逼近函式的區間。縮小區間可以針對要逼近的函式,利用許多不同的係數及增益來達到。現在的數學函式庫會將區間劃分為許多的小區間,每個區間搭配一個次數不高的多項式。
分類
1.最佳多項式
只要選定了多項式的次數及逼近的範圍,就可以用以使最壞情形誤差最小化的原則,來選擇逼近多項式,其目的為最小化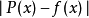 的絕對值,其中P(x)為逼近多項式,而f(x)為實際的函式。對於一個良態的函式,存在一個N次的多項式,使誤差曲線的大小在
的絕對值,其中P(x)為逼近多項式,而f(x)為實際的函式。對於一個良態的函式,存在一個N次的多項式,使誤差曲線的大小在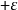 和
和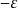 之間震盪至多N+2次,其最壞情形的誤差為
之間震盪至多N+2次,其最壞情形的誤差為 。一個N次的多項式可以內插曲線中的N+1個點。當然也有可能製造一些極端的函式,使得滿足上述條件的多項式不存在,但在實務上很少需要為這様的函式進行逼近。
。一個N次的多項式可以內插曲線中的N+1個點。當然也有可能製造一些極端的函式,使得滿足上述條件的多項式不存在,但在實務上很少需要為這様的函式進行逼近。
例如下圖中的紅線就是用N=4情形下用多項式逼近log(x)及exp(x)的誤差。誤差在和 之間震盪。每一個例子中的極端有N+2個,也就是6個。極值出現在區間的端點,也就是圖的最左邊及最右邊。
之間震盪。每一個例子中的極端有N+2個,也就是6個。極值出現在區間的端點,也就是圖的最左邊及最右邊。
說明:圖1——紅色是log(x)及最佳多項式的誤差,藍色是log(x)和Chebyshev逼近的誤差,x範圍都在[2, 4]區間內,縱軸的格線為10。最佳多項式的最大誤差為6.07 x 10;圖2——紅色是exp(x)及最佳多項式的誤差,藍色是exp(x)和Chebyshev逼近的誤差,x範圍都在[−1, 1]區間內,縱軸的格線為10。最佳多項式的最大誤差為5.47 x 10。
2.切比雪夫近似
若計算一函式切比雪夫展開的係數:

只展開到 項為止,可以得到一個逼近f(x)的N次多項式。
項為止,可以得到一個逼近f(x)的N次多項式。
對於一個有快速收斂冪級數的函式而言,若展開到一定項次後截止不再展開,截止產生的誤差接近截止後的第一項,因此誤差可以由截止後的第一項代表。若是用切比雪夫多項式展開,也會有一様的結果。若切比雪夫展開只展開到 ,後面截止,其誤差會接近
,後面截止,其誤差會接近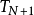 的整數倍。切比雪夫多項式的特點是在[−1, 1]區間以內.其數值會在+1和−1之間震盪。
的整數倍。切比雪夫多項式的特點是在[−1, 1]區間以內.其數值會在+1和−1之間震盪。 有N+2個極點。因此f(x)和切比雪夫展開的誤差接近一個有N+2個極點的函式,因此為近似最佳的N次多項式。
有N+2個極點。因此f(x)和切比雪夫展開的誤差接近一個有N+2個極點的函式,因此為近似最佳的N次多項式。
 圖3.切比雪夫逼近
圖3.切比雪夫逼近在上圖中,可以看到藍色線(切比雪夫近似的誤差)有時比紅色線(最佳多項式的誤差)接近x軸,但有時藍色線反而離x軸較遠,因此切比雪夫近似和最佳多項式畢竟還是有差異。不過exp函式是快速收斂的函式,切比雪夫近似的誤差會比log函式要好。
切比雪夫近似是數值積分方法Clenshaw–Curtis正交法的基礎。
3.雷米茲算法
雷米茲算法是在1934年由蘇俄數學家雷米茲提出的算法。可用來產生在一定區間內逼近函式f(x)的最佳多項式P(x)。雷米茲算法是一種疊代式的算法,最後會收斂到使誤差函式N+2個極值的多項式。
雷米茲算法是用以下的事實為基礎:可以在有N+2個測試點的情形下,創建一個N次多項式,其誤差函式在0附近震盪。
假設N+2個測試點 (其中
(其中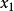 和
和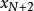 假設是區間的二個端點),需求解以下的多項式:
假設是區間的二個端點),需求解以下的多項式:

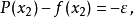
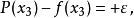
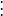
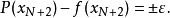
等式右側的正負號交替出現。因此可以得到下式:



既然 給定,其各次方的冪次也是已知,而
給定,其各次方的冪次也是已知,而 也是已知。上式就變成由N+2的線性方程組成的聯立方程.有N+2個變數,分別是
也是已知。上式就變成由N+2的線性方程組成的聯立方程.有N+2個變數,分別是 ,
, 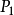 , ...,
, ...,  及
及 。可以解出上式的多項式P及誤差
。可以解出上式的多項式P及誤差 。
。
下圖產生一個在[−1, 1]區間內逼近 的四階多項式,六個測試點為 −1, −0.7, −0.1, +0.4, +0.9和1。在圖中將二端點以外的測試點標示綠色,其誤差
的四階多項式,六個測試點為 −1, −0.7, −0.1, +0.4, +0.9和1。在圖中將二端點以外的測試點標示綠色,其誤差 為4.43 x 10。
為4.43 x 10。
要產生在[−1, 1]區間內逼近{\displaystyle e^{x}}的四階多項式,依雷米茲算法的第一步計算逼近多項式的誤差。垂直的一格為10
 圖4.雷米茲算法實例圖
圖4.雷米茲算法實例圖注意到上圖在六個測試點上的誤差的確是 ,但極值不是在測試點上。若極值在測試點上(P(x)-f(x)在測試點上有最大值或最小值),在此這個區間的誤差都不會超過
,但極值不是在測試點上。若極值在測試點上(P(x)-f(x)在測試點上有最大值或最小值),在此這個區間的誤差都不會超過 ,此多項式即為最佳多項式。
,此多項式即為最佳多項式。
雷米茲算法的第二步就是將測試點移到誤差函式有最大值或最小值,例如上圖中−0.1的測試點需移到−0.28。移動的方式可以進行一輪牛頓法,來取新的測試點位置,由於知道P(x)−f(x)的一階及二階導數,因此可以大略計算測試點要移到哪裡才能使誤差函式的微分為零。計算多項式P(x)的一階及二階導數並不困難,但雷米茲算法需要可以計算f(x)的一階及二階導數,而且需要很高的精度,其精度需求要比雷米茲算法輸出期望的精度要高。
在移動測試點後,會產生新的線性聯立方程,求解後得到新的多項式,再利用牛頓法去找下一組測試點……,一直到結果收斂到需要的精度為止。雷米茲算法收斂速度很快,對於良態的函式,雷米茲算法是二次收斂,若測試點是在正確位置的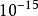 誤差範圍內,下次測試點是在正確位置的
誤差範圍內,下次測試點是在正確位置的 誤差範圍內。
誤差範圍內。
使用雷米茲算法時,一般會選切比雪夫多項式 的零點為初始測試點,因為最後的誤差函式會類似切比雪夫多項式。
的零點為初始測試點,因為最後的誤差函式會類似切比雪夫多項式。
