
基本介紹
- 中文名:置信集
- 外文名:confidence set
- 領域:數學
- 學科:數理統計
- 別稱:置信域
- 概念:置信區間
概念,置信區間,區間估計,參數估計,
概念
置信集(confidence set)亦稱置信域。置信區間概念推廣到多維的形式。設總體ξ的機率分布族為{Fθ(x),θ∈Θ},X=(X1,X2,…,Xn)是來自總體ξ的一個樣本,θ=(θ1,θ2,…,θk)∈Θ⊂R。如果S(X)滿足:
1.對任一個樣本觀測值x,S(x)是Θ的一個子集;
2.對給定的α(0<α<1)和一切θ∈Θ,有:Pθ(θ∈S(X))≥1-α,則稱S(X)是θ的置信水平為1-α的置信集,稱:
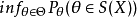
置信區間
由樣本值對總體進行估計時,在一定置信水平下的估計值的範圍。亦稱“置信域”。由美國統計學家奈曼(Neyman,J.)提出。在統計檢驗中,當估計一個未知的參數的值時,一般通過樣本的觀察值給出一個範圍,使得這個範圍能按照足夠大的機率(給定的)包含所要估計的參數,這個範圍就稱為置信區間。置信區間的確定,可根據樣本的觀察結果來確定θ1和θ2。當θ1和θ2對於給定的顯著水平θ(θ<1=滿足:θ1≤θ0≤θ2,則P (θ1≤θ0≤θ2) =1-α,θ0為待估計的參數;區間(θ1,θ2)為置信區間;θ1和θ2分別為置信下限和置信上限;1-α為置信係數,或置信機率,表明區間估計的可靠性,它是區間估計的可靠機率;α為顯著性水平,表明區間估計的不可靠機率。
置信區間是指由樣本統計量所構造的總體參數的估計區間。在統計學中,一個機率樣本的置信區間(Confidence interval)是對這個樣本的某個總體參數的區間估計。置信區間展現的是這個參數的真實值有一定機率落在測量結果的周圍的程度。置信區間給出的是被測量參數的測量值的可信程度,即前面所要求的“一個機率”。
區間估計
區間估計是根據樣本指標和抽樣誤差推斷總體指標落在某一區間範圍內的方法。它的數學定義是:設T1(X1, …,Xn),T2 (X1, …,Xn)為兩個統計量,若P {T1(X1,…,Xn)≤θ≤T2 (X1,…,Xn)} = 1-α成立,則稱〔T1,T2〕為θ的區間估計,T1稱為置信下限,T2稱為置信上限,1-α稱為置信度, 〔T1,T2〕稱為置信區間。α越小,1-α就越大, 區間[T1,T2]的距離就越大,θ落在[T1,T2]之間的機率也就越大;反之越小。α的值直接影響著區間估計的置信區間和置信度,α的值太小,估計區間太大,區間估計就失去了意義。α的值過大,估計區間過小,θ落在[T1,T2]之間的機率就越小,區間估計的置信度下降。通常對於給定的1-α, [T1,T2]有多種取法,因此, “最好”的置信區間應該是:在給定的較大的置信度1-α下(通常取1-α=0. 95),使[T1,T2]距離最小的區間估計是最好的區間估計。
參數估計
又稱“抽樣估計”、“母數估計”。推論性統計的一項基本內容,是用樣本統計值來估計總體參數值的一種統計方法。例如,要了解某市居民對住房分配的滿意程度,通常用抽樣調查所得到的樣本平均值、標準差與百分比等統計值來估計全市居民這一總體的平均值、標準差與百分比等參數值。參數估計可以分為點估計和區間估計。點估計是直接用樣本統計值來估計一個單一的總體參數值,所以又稱單值估計。點估計不考慮隨機變數的抽樣誤差和機率分布,因而不能反映估計的參數與真正的總體指標有多大的誤差以及估計的可靠程度。例如,假定上例中真正的總體指標是全市居民中42%的人對住房分配不太滿意,但調查的樣本統計值為40%,由於並不知道真正的總體指標為42%,所以不知道估計的參數與真正的總體指標有2%的誤差。又假如從同一總體中抽樣調查的另一個樣本統計值為38%,那么究竟把哪一個統計值作為總體參數值是可靠的呢?所以點估計無法反映估計的誤差和可靠程度。區間估計是以數值的區間形式來確定總體參數的可能範圍。它根據機率抽樣的理論,以一定的機率即可靠程度來保證真正的總體指標落在某一區間內。例如,假定上述對某市居民住房問題的調查,抽取的樣本統計值表明,該樣本中有40%的居民對住房不太滿意。如果這次抽樣是在95%的機率保證下進行的,其最大抽樣誤差為3%,這時就可以說,該總體真正的參數落在40%±3%的區間內,即全市居民有37%至43%的人對住房分配不太滿意,這一結論有95%的可靠程度。在輿論調查中,參數估計主要用於兩種情況:(1)用樣本平均數()來估計總體平均數(M);(2)用樣本比率(P)來估計總體比率(p)。上例就屬於用樣本比率來估計總體比率。區間估計中,以一定的機率即估計的可靠程度來保證總體參數落在某一區間內,這一區間的兩個極端值不會超過允許的誤差範圍,這種情況下的機率即估計的可靠程度就稱為可信度、置信度、可信係數或置信係數;這樣的區間即為所需估計參數的可信區間或置信區間。如上例中95%的機率即為這次估計的可信度,參數值落入的區間(37%至43%)即為這次估計的可信區間。
