
缺失值是指粗糙數據中由於缺少信息而造成的數據的聚類、分組、刪失或截斷。它指的是現有數據集中某個或某些屬性的值是不完全的。
基本介紹
- 中文名:缺失值
- 外文名:Missing value
- 拼音:Quē shī zhí
- 學科:數學
- 產生原因:機械和人為
- 處理方法:刪除個案和插補等
產生原因,類型,處理方法,注意事項,
產生原因
缺失值的產生的原因多種多樣,主要分為機械原因和人為原因。
機械原因是由於機械原因導致的數據收集或保存的失敗造成的數據缺失,比如數據存儲的失敗,存儲器損壞,機械故障導致某段時間數據未能收集(對於定時數據採集而言)。
人為原因是由於人的主觀失誤、歷史局限或有意隱瞞造成的數據缺失,比如,在市場調查中被訪人拒絕透露相關問題的答案,或者回答的問題是無效的,數據錄入人員失誤漏錄了數據。
類型
缺失值從缺失的分布來講可以分為完全隨機缺失,隨機缺失和完全非隨機缺失。
完全隨機缺失(missing completely at random,MCAR)
指的是數據的缺失是隨機的,數據的缺失不依賴於任何不完全變數或完全變數。
隨機缺失(missing at random,MAR)
指的是數據的缺失不是完全隨機的,即該類數據的缺失依賴於其他完全變數。
完全非隨機缺失(missing not at random,MNAR)
指的是數據的缺失依賴於不完全變數自身。
單值缺失
如果所有的缺失值都是同一屬性,那么這種缺失成為單值缺失。
任意缺失
如果缺失值屬於不同的屬性,稱為任意缺失。
單調缺失
對於時間序列類的數據,可能存在隨著時間的缺失,這種缺失稱為單調缺失。
處理方法
對於缺失值的處理,從總體上來說分為刪除存在缺失值的個案和缺失值插補。對於主觀數據,人將影響數據的真實性,存在缺失值的樣本的其他屬性的真實值不能保證,那么依賴於這些屬性值的插補也是不可靠的,所以對於主觀數據一般不推薦插補的方法。插補主要是針對客觀數據,它的可靠性有保證。
1.刪除含有缺失值的個案
主要有簡單刪除法和權重法。簡單刪除法是對缺失值進行處理的最原始方法。它將存在缺失值的個案刪除。如果數據缺失問題可以通過簡單的刪除小部分樣本來達到目標,那么這個方法是最有效的。當缺失值的類型為非完全隨機缺失的時候,可以通過對完整的數據加權來減小偏差。把數據不完全的個案標記後,將完整的數據個案賦予不同的權重,個案的權重可以通過logistic或probit回歸求得。如果解釋變數中存在對權重估計起決定行因素的變數,那么這種方法可以有效減小偏差。如果解釋變數和權重並不相關,它並不能減小偏差。對於存在多個屬性缺失的情況,就需要對不同屬性的缺失組合賦不同的權重,這將大大增加計算的難度,降低預測的準確性,這時權重法並不理想。
2.可能值插補缺失值
(1)均值插補。數據的屬性分為定距型和非定距型。如果缺失值是定距型的,就以該屬性存在值的平均值來插補缺失的值;如果缺失值是非定距型的,就根據統計學中的眾數原理,用該屬性的眾數(即出現頻率最高的值)來補齊缺失的值。
(2)利用同類均值插補。同均值插補的方法都屬於單值插補,不同的是,它用層次聚類模型預測缺失變數的類型,再以該類型的均值插補。假設X= (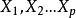 )為信息完全的變數,Y為存在缺失值的變數,那么首先對X或其子集行聚類,然後按缺失個案所屬類來插補不同類的均值。如果在以後統計分析中還需以引入的解釋變數和Y做分析,那么這種插補方法將在模型中引入自相關,給分析造成障礙。
)為信息完全的變數,Y為存在缺失值的變數,那么首先對X或其子集行聚類,然後按缺失個案所屬類來插補不同類的均值。如果在以後統計分析中還需以引入的解釋變數和Y做分析,那么這種插補方法將在模型中引入自相關,給分析造成障礙。
(3)極大似然估計(Max Likelihood ,ML)。在缺失類型為隨機缺失的條件下,假設模型對於完整的樣本是正確的,那么通過觀測數據的邊際分布可以對未知參數進行極大似然估計(Little and Rubin)。這種方法也被稱為忽略缺失值的極大似然估計,對於極大似然的參數估計實際中常採用的計算方法是期望值最大化(Expectation Maximization,EM)。該方法比刪除個案和單值插補更有吸引力,它一個重要前提:適用於大樣本。有效樣本的數量足夠以保證ML估計值是漸近無偏的並服從常態分配。但是這種方法可能會陷入局部極值,收斂速度也不是很快,並且計算很複雜。
(4)多重插補(Multiple Imputation,MI)。多值插補的思想來源於貝葉斯估計,認為待插補的值是隨機的,它的值來自於已觀測到的值。具體實踐上通常是估計出待插補的值,然後再加上不同的噪聲,形成多組可選插補值。根據某種選擇依據,選取最合適的插補值。多重插補方法分為三個步驟:①為每個空值產生一套可能的插補值,這些值反映了無回響模型的不確定性;每個值都可以被用來插補數據集中的缺失值,產生若干個完整數據集合。②每個插補數據集合都用針對完整數據集的統計方法進行統計分析。③對來自各個插補數據集的結果,根據評分函式進行選擇,產生最終的插補值。
多重插補和貝葉斯估計的思想是一致的,但是多重插補彌補了貝葉斯估計的幾個不足。第一,貝葉斯估計以極大似然的方法估計,極大似然的方法要求模型的形式必須準確,如果參數形式不正確,將得到錯誤得結論,即先驗分布將影響後驗分布的準確性。而多重插補所依據的是大樣本漸近完整的數據的理論,在數據挖掘中的數據量都很大,先驗分布將極小的影響結果,所以先驗分布的對結果的影響不大。第二,貝葉斯估計僅要求知道未知參數的先驗分布,沒有利用與參數的關係。而多重插補對參數的聯合分布作出了估計,利用了參數間的相互關係。
同時,多重插補保持了單一插補的兩個基本優點,即套用完全數據分析方法和融合數據收集者知識的能力。相對於單一插補,多重插補有三個極其重要的優點:第一,為表現數據分布,隨機抽取進行插補,增加了估計的有效性。第二,當多重插補是在某個模型下的隨機抽樣時,按一種直接方式簡單融合完全數據推斷得出有效推斷,即它反映了在該模型下由缺失值導致的附加變異。第三,在多個模型下通過隨機抽取進行插補,簡單地套用完全數據方法,可以對無回答的不同模型下推斷的敏感性進行直接研究。
多重插補也有以下缺點:①生成多重插補比單一插補需要更多工作;②貯存多重插補數據集需要更多存儲空間;③分析多重插補數據集比單一插補需要花費更多精力。
以上四種插補方法,對於缺失值的類型為隨機缺失的插補有很好的效果。兩種均值插補方法是最容易實現的,也是以前人們經常使用的,但是它對樣本存在極大的干擾,尤其是當插補後的值作為解釋變數進行回歸時,參數的估計值與真實值的偏差很大。相比較而言,極大似然估計和多重插補是兩種比較好的插補方法,與多重插補對比,極大似然缺少不確定成分,所以越來越多的人傾向於使用多值插補方法。
注意事項
在許多實際問題的研究中,有一些數據無法獲得或缺失。當缺失比例很小時,可直接對完全記錄進行數據處理,捨棄缺失記錄。 但在實際數據中,往往缺失數據占有相當的比重,尤其是多元數據。這時刪除個案的處理將是低效率的,因為這樣做丟失了大量信息,並且會產生偏倚,使不完全觀測數據與完全觀測數據間產生系統差異。
而插補處理只是將未知值補以我們的主觀估計值,不一定完全符合客觀事實。以上的分析都是理論分析,對於缺失值由於它本身無法觀測,也就不可能知道它的缺失所屬類型,也就無從估計一個插補方法的插補效果。另外這些方法通用於各個領域,具有了普遍性,那么針對一個領域的專業的插補效果就不會很理想,正是因為這個原因,很多專業數據挖掘人員通過他們對行業的理解,手動對缺失值進行插補的效果反而可能比這些方法更好。缺失值的插補是在數據挖掘過程中為了不放棄大量的信息,而採用的人為干涉缺失值的情況,無論是那種處理方法都會影響變數間的相互關係,在對不完備信息進行補齊處理的同時,我們或多或少地改變了原始的數據的信息系統,對以後的分析存在潛在的影響,所以對缺失值的處理一定要慎重。
