")
馬爾可夫決策過程(Markov Decision Process, MDP)是序貫決策(sequential decision)的數學模型,用於在系統狀態具有馬爾可夫性質的環境中模擬智慧型體可實現的隨機性策略與回報。MDP的得名來自於俄國數學家安德雷·馬爾可夫(Андрей Андреевич Марков),以紀念其為馬爾可夫鏈所做的研究。
MDP基於一組互動對象,即智慧型體和環境進行構建,所具有的要素包括狀態、動作、策略和獎勵。在MDP的模擬中,智慧型體會感知當前的系統狀態,按策略對環境實施動作,從而改變環境的狀態並得到獎勵,獎勵隨時間的積累被稱為回報。
MDP的理論基礎是馬爾可夫鏈,因此也被視為考慮了動作的馬爾可夫模型。在離散時間上建立的MDP被稱為“離散時間馬爾可夫決策過程(descrete-time MDP)”,反之則被稱為“連續時間馬爾可夫決策過程(continuous-time MDP)”。此外MDP存在一些變體,包括部分可觀察馬爾可夫決策過程、約束馬爾可夫決策過程和模糊馬爾可夫決策過程。
在套用方面,MDP被用於機器學習中強化學習(reinforcement learning)問題的建模。通過使用動態規劃、隨機採樣等方法,MDP可以求解使回報最大化的智慧型體策略,並在自動控制、推薦系統等主題中得到套用。
基本介紹
- 中文名:馬爾可夫決策過程
- 外文名:Markov Decision Processes, MDP
- 類型:馬爾可夫模型,決策模型
- 提出者:Richard Bellman,Ronald Howard,David Blackwell
- 提出時間:1957-1962年
- 學科:統計學,機器學習
- 套用:運籌學,自動控制,機器人學
歷史,定義,理論與性質,轉移理論,折現,值函式,算法,值函式算法,策略搜尋算法,推廣,套用,
歷史
MDP的歷史可以追溯至20世紀50年代動力系統研究中的最優控制(optimal control)問題,1957年,美國學者Richard Bellman通過離散隨機最優控制模型首次提出了離散時間馬爾可夫決策過程。1960年和1962年,美國學者Ronald A. Howard和David Blackwell提出並完善了求解MDP模型的動態規劃方法。
進入1980s後,學界對MDP的認識逐漸由“系統最佳化”轉為“學習”。1987年,美國學者Paul Werbos在研究中試圖將MDP和動態規劃與大腦的認識機制相聯繫。1989年,英國學者Chris Watkins首次在強化學習中嘗試使用MDP建模。Watkins (1989)在發表後得到了機器學習領域的關注,MDP也由此作為強化學習問題的常見模型而得到套用。
定義
MDP是在環境中模擬智慧型體的隨機性策略(policy)與回報的數學模型,且環境的狀態具有馬爾可夫性質。 MDP中智慧型體與環境的互動
MDP中智慧型體與環境的互動
MDP中智慧型體與環境的互動互動對象與模型要素
由定義可知,MDP包含一組互動對象,即智慧型體和環境:
- 智慧型體(agent):MDP中進行機器學習的代理,可以感知外界環境的狀態進行決策、對環境做出動作並通過環境的反饋調整決策。
- 環境(environment):MDP模型中智慧型體外部所有事物的集合,其狀態會受智慧型體動作的影響而改變,且上述改變可以完全或部分地被智慧型體感知。環境在每次決策後可能會反饋給智慧型體相應的獎勵。
按定義,MDP包含5個模型要素,狀態(state)、動作(action)、策略(policy)、獎勵(reward)和回報(return),其符號與說明在表中給出:
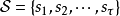




在表中建模要素的基礎上,MDP按如下方式進行組織:智慧型體對初始環境




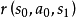

連續與離散MDP
MDP的指數集(index set)是時間步: ,並按時間步進行演化(evolution)。時間步離散的MDP被稱為離散時間馬爾科夫決策過程(descrete-time MDP),反之則被稱為連續時間馬爾科夫決策過程(continuous-time MDP),二者的關係可類比連續時間馬爾可夫鏈與離散時間馬爾可夫鏈。
,並按時間步進行演化(evolution)。時間步離散的MDP被稱為離散時間馬爾科夫決策過程(descrete-time MDP),反之則被稱為連續時間馬爾科夫決策過程(continuous-time MDP),二者的關係可類比連續時間馬爾可夫鏈與離散時間馬爾可夫鏈。
圖模型
MDP可以用圖模型表示,在邏輯上類似於馬爾可夫鏈的轉移圖。MDP的圖模型包含狀態節點和動作節點,狀態到動作的邊由策略定義,動作到狀態的邊由環境動力項(參見求解部分)定義。除初始狀態外,每個狀態都返回一個獎勵。 MDP的圖模型表示
MDP的圖模型表示
MDP的圖模型表示解釋性的例子:多臂賭博機
多臂賭博機問題(multi-armed bandit problem)的設定如下:給定K個不同的賭博機,拉動每個賭博機的拉桿,賭博機會按照一個事先設定的機率掉錢或不掉錢。每個賭博機掉錢的機率不一樣。MDP可以模擬智慧型體選擇賭博機的策略和回報。在該例子中,MDP的要素有如下對應:
“環境”是K個相互獨立的賭博機;“狀態”是“掉錢”和“不掉錢”,其馬爾可夫性質在於每次使用賭博機,返回結果都與先前的使用記錄無關;“動作”是使用賭博機;“策略”是依據前一次操作的賭博機和其返回狀態,選擇下一次使用的賭博機;“獎勵”是一次使用賭博機後掉錢的金額;回報是多次使用賭博機獲得的總收益。
與多臂賭博機類似的例子包括廣告推薦系統和風險投資組合,在MDP建模後,此類問題被視為離散時間步下的紀元式強化學習。
理論與性質
轉移理論
馬爾可夫性質與轉移機率
按定義,MDP具有馬爾可夫性質,按條件機率關係可表示如下: 即當前時刻的狀態僅與前一時刻的狀態和動作有關,與其他時刻的狀態和動作條件獨立。等式右側的條件機率被稱為MDP的狀態間的轉移機率。馬爾可夫性質是所有馬爾可夫模型共有的性質,但相比於馬爾可夫鏈,MDP的轉移機率加入了智慧型體的動作,其馬爾可夫性質也與動作有關。
即當前時刻的狀態僅與前一時刻的狀態和動作有關,與其他時刻的狀態和動作條件獨立。等式右側的條件機率被稱為MDP的狀態間的轉移機率。馬爾可夫性質是所有馬爾可夫模型共有的性質,但相比於馬爾可夫鏈,MDP的轉移機率加入了智慧型體的動作,其馬爾可夫性質也與動作有關。
MDP的馬爾可夫性質是其被套用於強化學習問題的重要原因,強化學習問題在本質上要求環境的下個狀態與所有的歷史信息,包括狀態、動作和獎勵有關,但在建模時採用馬爾可夫假設可以在對問題進行簡化的同時保留主要關係,此時環境的單步動力學就可以對其未來的狀態進行預測。因此即便一些環境的狀態信號不具有馬爾可夫性,其強化學習問題也可以使用MDP建模。
軌跡
在此基礎上,類比馬爾可夫鏈中的樣本軌道(sample path),可定義MDP的軌跡(trajectory):

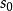
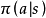

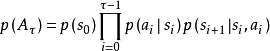
折現
MDP的時間步可以是有限或無限的。時間步有限的MDP存在一個終止狀態(terminal state),該狀態被智慧型體觸發後,MDP的模擬完成了一個紀元(episode)並得到回報。與之對應的,環境中沒有終止狀態的MDP可擁有無限的時間步,其回報也會趨於無窮。 MDP的軌跡與回報計算示例,方形為終止狀態
MDP的軌跡與回報計算示例,方形為終止狀態
MDP的軌跡與回報計算示例,方形為終止狀態在對實際問題建模時,除非無限時間步的MDP有收斂行為,否則考慮無限遠處的回報是不適合的,也不利於MDP的求解。為此,可引入折現機制並得到折現回報(discounted return):


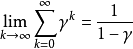
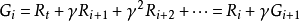
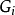

值函式
參見:強化學習


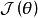
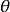
狀態值函式(state value function)
在MDP模擬的一個紀元中,目標函式與初始狀態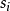 有關,因此按定義,目標函式有可有如下展開:
有關,因此按定義,目標函式有可有如下展開:
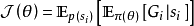
目標函式中包含初始狀態的條件數學期望被定義為狀態值函式: ,即智慧型體由初始狀態開始,按策略
,即智慧型體由初始狀態開始,按策略 決定後續動作所得回報的數學期望:
決定後續動作所得回報的數學期望:
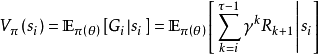

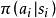
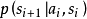

動作值函式(action value function)
狀態值函式中的條件機率: 表示環境對動作的回響,該項也被稱為環境動力項(environment dynamics)。環境動力項不受智慧型體控制,其數學期望可以定義為動作值函式或Q函式:
表示環境對動作的回響,該項也被稱為環境動力項(environment dynamics)。環境動力項不受智慧型體控制,其數學期望可以定義為動作值函式或Q函式: ,表示智慧型體由給定的狀態
,表示智慧型體由給定的狀態 和動作
和動作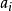 開始,並按策略
開始,並按策略 決定後續動作所得到的回報數學期望:
決定後續動作所得到的回報數學期望:

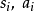
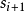

狀態值函式和動作值函式是一些MDP算法需要使用的,目標函式的變體,其實際意義是對策略的評估。例如在狀態 ,若有一個新的動作
,若有一個新的動作 使得
使得 ,則實施新動作比當前策略
,則實施新動作比當前策略 給出的動作要好,因此可通過算法增加新動作所對應的策略
給出的動作要好,因此可通過算法增加新動作所對應的策略 的機率。
的機率。
算法
參見:強化學習
在MDP模型建立後,強化學習算法能夠求解一組貫序策略: ,使得目標函式,即智慧型體的折現回報,取全局最大值:
,使得目標函式,即智慧型體的折現回報,取全局最大值:

值函式算法
動態規劃(dynamic programming)
參見:動態規劃
作為貝爾曼最最佳化原理(Bellman's principle of Optimality)的推論,有限時間步的MDP至少存在一個全局最優解,且該最優解是確定的(deterministic),可使用動態規劃求得。
使用動態規劃求解的MDP屬於“基於模型的強化學習(model-based reinforcement learning),因為要求狀態值函式和動作值函式的貝爾曼方程已知,而後者等價於MDP的環境不是”黑箱“,其環境動力項 是已知的。MDP的動態規劃分為策略疊代(policy iteration)和值疊代(value iteration)兩種,其核心思想是最最佳化原理:最優策略的子策略在一次疊代中也是以該狀態出發的最優策略,因此在疊代中不斷選擇該次疊代的最優子策略能夠收斂至MDP的全局最優。
是已知的。MDP的動態規劃分為策略疊代(policy iteration)和值疊代(value iteration)兩種,其核心思想是最最佳化原理:最優策略的子策略在一次疊代中也是以該狀態出發的最優策略,因此在疊代中不斷選擇該次疊代的最優子策略能夠收斂至MDP的全局最優。
以策略疊代為例,在對MDP的建模要素初始化後,其每次疊代都使用貝爾曼方程計算狀態值函式以評估策略,並按動作值函式對狀態值函式的貝爾曼方程確定當前狀態下的最優動作和策略: ,疊代在策略的前後變化小於疊代精度時收斂。
,疊代在策略的前後變化小於疊代精度時收斂。
隨機模擬
以蒙特卡羅方法和時序差分學習(temporal-difference learning)為代表的MDP算法屬於“無模型的強化學習(model-free reinforcement learning)”,適用於MDP的環境動力項未知的情形。在MDP的轉移機率未知時,狀態值函式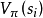 無法參與最佳化,因此隨機模擬方法通過生成隨機數直接估計動作值函式的真實值並求解MDP。
無法參與最佳化,因此隨機模擬方法通過生成隨機數直接估計動作值函式的真實值並求解MDP。
對給定的初始狀態和動作,蒙特卡羅方法按N次隨機遊走試驗所得回報的平均估計動作值函式:

時序差分學習可視為蒙特卡羅方法和動態規劃的結合。在使用採樣方法估計動作值函式時,時序差分學習將採樣改寫為貝爾曼方程的形式,以更高的效率更新動作值函式的取值。求解MDP可用的時序差分學習算法包括SARSA 算法(State Action RewardState Action, SARSA)和Q學習(Q-Learning)算法,二者都利用了MDP的馬爾可夫性質,但前者的改進策略和採樣策略是同一個策略,因此被稱為“同策略(on policy)”算法,而後者採樣與改進分別使用不同策略,因此被稱為“異策略(off policy)”算法。
策略搜尋算法
參見:策略搜尋
策略搜尋(policy search)可以在策略空間直接搜尋MDP的最優策略完成求解。策略搜尋算法的常見例子包括REINFORCE算法和演員-評論員算法(Actor-Critic Algorithm)。REINFORCE算法使用隨機梯度上升求解(可微分的)策略函式的參數使得目標函式最大,一些REINFORCE算法的改進版本通過引入基準線加速疊代的收斂。演員-評論員算法是一種結合策略搜尋和時序差分學習的方法。其中“演員(actor)”是指策略函式,即學習一個策略來得到儘量高的回報,“評論員(critic)”是狀態值函式,對當前策略的值函式進行估計,即評估演員的好壞。藉助於值函式,Actor-Critic 算法可以進行單步更新參數。
推廣
約束馬爾可夫決策過程
約束馬爾可夫決策過程(Constrained MDP, CMDP)是對智慧型體施加了額外限制的MDP,在CMDP中,智慧型體不僅要實施策略和獲得回報,還要確保環境狀態的一些指標不超出限制。例如在基於MDP的投資組合問題中,智慧型體除了最大化投資回報,也要求限制投資風險;在交通管理中,智慧型體除了最大化車流量,也要求限制車輛的平均延遲和特定路段的車輛通行種類。
相比於MDP,CMDP中智慧型體的每個動作都對應多個(而非一個)獎勵。此外,由於約束的引入,CMDP不滿足貝爾曼最最佳化原理,其最優策略是對初始狀態敏感的,因此CMDP無法使用動態規劃求解。離散CMDP的常見解法是線性規劃(linear programming)。
模糊馬爾可夫決策過程
模糊馬爾可夫決策過程(Fuzzy MDP, FMDP)是使用模糊動態規劃(fuzzy dynamic programming)求解的MDP模型,是MDP的推廣之一。FMDP的求解方法屬於值函式算法,其中策略評估部分與傳統的動態規劃方法相同,但策略改進部分使用了模糊推理(fuzzy inference),即值函式被用作模糊推理的輸入,策略的改進是模糊推理系統的輸出。
部分可觀察馬爾可夫決策過程
主條目:部分可觀察馬爾可夫決策過程
在一些設定中,智慧型體無法完全觀測環境的狀態,此類MDP被稱為部分可觀察馬爾可夫決策過程(Partially Observable MDP,POMDP)。POMDP是一個馬爾可夫決策過程的泛化。POMDP與MDP的馬爾可夫性質相同,但是POMDP框架下智慧型體只能知道部分狀態的觀測值。比如在自動駕駛中,智慧型體只能感知感測器採集的有限的環境信息。與MDP相比,POMDP包含兩個額外的模型要素:智慧型體的觀測機率 和觀測空間
和觀測空間 。
。
