設 X1,X2, …, Xn是取自總體X的樣本,X(i) 稱為該樣本的第i個次序統計量,它的取值是將樣本觀測值由小到大排列後得到的第i個觀測值。從小到大排序為x(1),x(2), …,x(n),則稱X(1),X(2), …,X(n)為順序統計量。
基本介紹
- 中文名:次序統計量
- 外文名:Ordered Statistics
- 領域:數學
- 屬性:樣本觀測值由小到大排列的觀測值
- 性質:充分統計量
- 相關名詞:順序統計量
簡介,次序統計量的性質,單個次序統計量的分布,多個次序統計量的聯合分布,
簡介
設 X1,X2,…, Xn是取自總體X的樣本,X(i) 稱為該樣本的第i個次序統計量,它的取值是將樣本觀測值由小到大排列後得到的第i個觀測值。從小到大排序為x(1),x(2), …,x(n),則稱X(1),X(2), …,X(n)為順序統計量。
顯然:

(1) 最小順序統計量
(2)最大順序統計量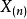
(3) 極差(Range)
(4)四分位極差(iql)
樣本X1,X2,…,Xn是獨立同分布的,而次序統計量X(1),X(2),…,X(n) 則既不獨立,分布也不相同。
次序統計量的性質
次序統計量是充分統計量
證明:
由充分統計量的定義可知,只需要證明其條件分布與總體分布無關即可.由於樣本具有獨立性與同分布性,因而



其中, 是
是 的一個置換,這樣的置換共有
的一個置換,這樣的置換共有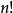 ,由此可見,此條件分布與總體無關,故次序統計量是充分統計量。
,由此可見,此條件分布與總體無關,故次序統計量是充分統計量。
單個次序統計量的分布
設總體X的密度函式為f(x),分布函式為F(x), X1, X2,…, Xn為樣本,則第k個次序統計量X(k)的密度函式為

證明:k=1,n時,直接可得
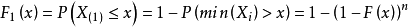

多個次序統計量的聯合分布
對任意多個次序統計量可給出其聯合分布,以兩個為例說明:
(1)次序統計量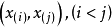 的聯合分布密度函式為:
的聯合分布密度函式為:

(2)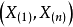 的聯合分布密度(連續型)為:
的聯合分布密度(連續型)為:


