
基本介紹
- 中文名:全模型
- 外文名:Full Model
- 別稱:飽和模型
- 簡介:包含所有自變數的線性回歸模型
- 所屬學科:數學
- 所屬問題:數理統計
基本介紹,自變數選擇對估計和預測的影響,
基本介紹
設有一個因變數Y和m個自變數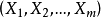 構成的線性回歸模型為:
構成的線性回歸模型為:
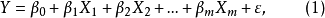
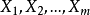
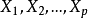

我們稱其為選模型。
自變數選擇對估計和預測的影響
我們可以將上面關於自變數的選擇問題看成是選用全模型還是選模型去描述一個實際問題。如果應該用全模型描述實際問題,而我們卻選擇了選模型,則說明我們在建立模型時就丟掉了一些有用的自變數;反之,如果應該用選模型,而我們卻使用了全模型,則說明我們將一些不必要的自變數引進了模型。兩種情況都屬於因自變數而導致的模型設定的錯誤。那么,模型自變數選擇的不當會給參數估計或模型的套用(如對因變數的預測)帶來什麼影響呢?
為了方便起見,我們把模型(1)的參數向量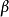 和隨機誤差項
和隨機誤差項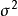 的估計量記為:
的估計量記為:
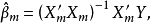
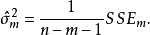
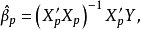
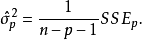
1)若已知全模型正確而誤用了選模型,當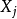 與
與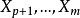 的相關係數不全為零時,則選模型的回歸係數的最小二乘估計是全模型相應參數的有偏估計。
的相關係數不全為零時,則選模型的回歸係數的最小二乘估計是全模型相應參數的有偏估計。
2)若已知全模型正確,當給定新的自變數值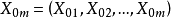 時,因變數的估計值為:
時,因變數的估計值為:
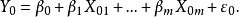
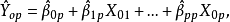
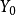
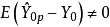
3)從預測的殘差來看,選模型的預測殘差為:
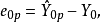
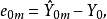
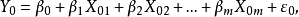
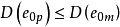
4)如果選模型正確,從無偏性的角度看,選模型的預測值為:
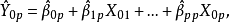
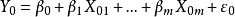
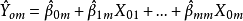
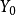
從預測方差的角度看,選模型的預測方差小於全模型的預測方差。從均方預測誤差的角度看,全模型的均方誤差包含預測方差和預測偏差的平方兩部分,而選模型的均方誤差僅包含預測方差這一項,且小於全模型,因而全模型的預測誤差將會更大。
可見,一個好的回歸模型,並不是考慮自變數越多越好或精度越高越好。在建立回歸模型時,選擇自變數的基本指導思想是少而精。有時可能漏掉了一些對因變數Y還有些影響但影響並不十分大的自變數,這時由於選模型估計的回歸係數的方差,要比由全模型所估計的相應變數的回歸係數的方差小。此外,對於所預測的因變數的方差來說也是如此,少了一些對因變數y有影響的自變數後,會導致估計量是有偏的。然而,儘管估計量是有偏的,但其預測偏差的方差會下降。
如果保留下來的自變數中有些對因變數不太重要,那么方程中包括這些變數就會導致模型參數的估計和因變數預測的有偏性與精度的降低。因此,建立回歸模型時,應儘可能剔除那些可有可無的自變數。
