
數據挖掘(Data mining)是用人工智慧、機器學習、統計學和資料庫的交叉方法在相對較大型的數據集中發現模式的計算過程。訓練數據是指數據挖掘過程中用於訓練數據挖掘模型的數據。訓練數據選擇一般有以下要求:數據樣本儘可能大、數據多樣化,數據樣本質量較高。
基本介紹
- 中文名:訓練數據
- 外文名:Train Data
- 學科:計算機
- 要求:數據樣本大且全
- 有關數據:數據挖掘、測試數據
- 階段:訓練模型
簡介,數據挖掘,自助法,
簡介
訓練數據(Train Data)即數據挖掘過程中用於數據挖掘模型構建的數據。在數據挖掘過程中,除了訓練數據還有測試數據(Test Data),即用於檢測模型構建,此數據只在模型檢驗時使用,用於評估模型的準確率。絕對不允許用於模型構建過程,否則會導致過渡擬合。驗證數據(Validation Data):可選,用於輔助模型構建,可以重複使用。當數據集較小,會採用一些方法來來彌補這個缺點,如自助法。
數據挖掘
數據挖掘(Data mining)是一個跨學科的計算機科學分支。數據挖掘有以下這些不同的定義:
“從數據中提取出隱含的過去未知的有價值的潛在信息”,
“一門從大量數據或者資料庫中提取有用信息的科學”。
數據挖掘運行是使用數據挖掘的設定對數據挖掘模型的計算。數據挖掘標準依據數據挖掘技術可 處理運行的過程,提出並規範了通常所用的四個計 算階段:
(1)訓練階段(training phase): 這是所有數據挖掘技術公用的,用於計算數據挖掘模型的階段。該 階段在建立模型前需要準備數據並做預處理。在預 處理時要定義識別欄位分配給有關的信息,如挖掘 類型和特定的控制欄位。在分類和回歸技術中用的 訓練階段還要有一個確認處理,稱確認階段,作為 數據挖掘分類和回歸技術訓練階段的一部分。它給數據挖掘模型輸入另外的數值組,可作為測試階段 的描述,其結果作為實例以決定運算法則結束時間。
(2)模型自查階段(model introspection phase): 也是所有數據挖掘技術普遍使用,用以解釋和評估 模型。將模型與目標一起細查,揭示訓練階段中數 據的相關性,以期達到兩個目的: ①找出數據中潛 在的規律,有助於進一步解釋模型; ②找出有統計 價值的特性,有助於評估模型的質量。
(3)測試階段(testing phase): 只用於分類和回 歸。測試時為模型的對象欄位讀入系列數值組,在 套用中評估每個數值組,將預測數值和對象欄位里 的實際數值做比較,其結果可為使用者或套用提供 實例,以此決定模型以質量為基礎能否套用於實際。
(4)套用階段(application phase): 模型套用期間 輸入數據組用來評估模型,或用較多的數據組來計 算模型。為了能正確地使用模型的輸入值,必須將 其分配到訓練階段確認的相關欄位中。一個預定課 題的模型套用,產生一個表可以控制相關的其他課 題。模型由一個或多個規則的特定輸入而得出推論, 推論結果可與附加特性一併提交。特定情況下,推 論是對模型可信度的支持。
這幾個階段不是一次完成的,數據挖掘運行當 包括訓練階段時調用訓練階段運行,當包括測試階 段時調用測試階段運行。其中某些階段要反覆多次, 各項功能也不是獨立實現的,有時要幾種方法互相 聯繫才能發揮作用。
自助法
自助法由Bradley Efron於1979年在《Annals of Statistics》上發表。是以自助採樣(bootstrap sampling)為基礎。給定包含m個樣本的數據集D,我們對它進行採樣產生數據集 D′:每次隨機從D中挑選出一個樣本,將其拷貝放入D′, 然後再將該樣本放回初始數據集D中,使得該樣本在下次採樣時仍有可能被採樣到;這個過程重複執行m次後,我們就得到可包含m個樣本數據的數據集D′,這就是自助採樣的結果.樣本在m次採樣中始終不被採到到機率為
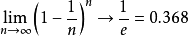
由此可知通過自助採樣,初始數據集D中約有36.8%的樣本未出現在採樣數據集D′中。於是我們可將D′ 用作訓練集,D∖D′用作測試集。
優缺點:自助法在數據集較小,難以有效劃分訓練/測試集時很有用,但是,自助法改變了初始數據集的分布,這會引入估計偏差,所以在數據量足夠時,一般採用留出法和交叉驗證法。
