
基本介紹
生成特徵臉,實現,計算特徵向量,套用,相關領域,
生成特徵臉
一組特徵臉可以通過在一大組描述不同人臉的圖像上進行主成分分析(PCA)獲得。任意一張人臉圖像都可以被認為是這些標準臉的組合。例如,一張人臉圖像可能是特徵臉1的10%,加上特徵臉2的55%,在減去特徵臉3的3%。值得注意的是,它不需要太多的特徵臉來獲得大多數臉的近似組合。另外,由於人臉是通過一系列向量(每個特徵臉一個比例值)而不是數字圖像進行保存,可以節省很多存儲空間。
實現
以下是特徵臉的實現過程:
- 減去均值向量. 均值向量a要首先計算,並且T中的每一個圖像都要減掉均值向量。
- 選擇主成分。一個DxD的協方差矩陣會產生D個特徵向量,每一個對應R×c圖像空間中的一個方向。具有較大特徵值的特徵向量會被保留下來,一般選擇最大的N個,或者按照特徵值的比例進行保存,如保留前95%。
這些特徵臉現在可以用於標識已有的和新的人臉:我們可以將一個新的人臉圖像(先要減去均值圖像)投影到特徵臉上,以此來記錄這個圖像與平均圖像的偏差。每一個特徵向量的特徵值代表了訓練集合的圖像與均值圖像在該方向上的偏差有多大。將圖像投影到特徵向量的子集上可能丟失信息,但是通過保留那些具有較大特徵值的特徵向量的方法可以減少這個損失。例如,如果當前處理一個100 x 100的圖像,就會得到10000個特徵向量。在實際使用中,大多數的圖像可以投影到100到150個特徵向量上進行識別,因此,10000個特徵向量的絕大多數可以丟棄。
計算特徵向量
設T是預處理圖像的矩陣,每一列對應一個減去均值圖像之後的圖像。則,協方差矩陣為S=TTT,並且對S的特徵值分解為


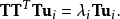
套用
特徵臉的最直接的套用就是人臉識別。在這個需求下,特徵臉相比其他手段在效率方面比較有優勢,因為特徵臉的計算速度非常快,短時間就可以處理大量人臉。但是,特徵臉在實際使用時有個問題,就是在不同的光照條件和成像角度時,會導致識別率大幅下降。因此,使用特徵臉需限制使用者在統一的光照條件下使用正面圖像進行識別。
