
基本介紹
- 中文名:損失函式
- 外文名:loss function
- 類型:函式
- 學科:統計學
- 套用:機器學習,經濟學,控制理論
定義,分類,回歸問題,分類問題,套用,案例一,案例二,
定義
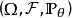
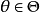
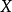
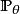
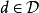
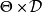
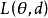
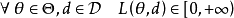

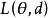
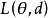
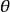
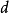
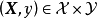
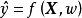
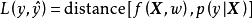
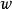
分類
回歸問題
回歸問題所對應的損失函式為L2損失函式和L1損失函式,二者度量了模型估計值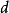 與觀測值
與觀測值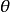 之間的差異:
之間的差異:
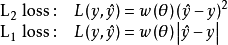
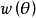
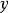
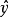
分類問題
分類問題所對應的損失函式為0-1損失,其是分類準確度的度量,對分類正確的估計值取0,反之取1:
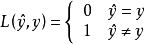
這裡給出二元分類(binary classification)中0-1損失函式的代理損失:
| 名稱 | 表達式 |
|---|---|
鉸鏈損失函式(hinge loss function) |  |
交叉熵損失函式(cross-entropy loss function) | 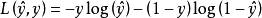 |
指數損失函式(exponential loss function) | 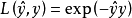 |
、交叉熵損失(點)、指數損失(虛線)") 鉸鏈損失(實線)、交叉熵損失(點)、指數損失(虛線)
鉸鏈損失(實線)、交叉熵損失(點)、指數損失(虛線)鉸鏈損失函式是一個分段連續函式,其在分類器分類完全正確時取0。使用鉸鏈損失對應的分類器是支持向量機(Support Vector Machine, SVM),鉸鏈損失的性質決定了SVM具有稀疏性,即分類正確但機率不足1和分類錯誤的樣本被識別為支持向量(support vector)被用於劃分決策邊界,其餘分類完全正確的樣本沒有參與模型求解。
交叉熵損失函式是一個平滑函式,其本質是信息理論(information theory)中的交叉熵(cross entropy)在分類問題中的套用。由交叉熵的定義可知,最小化交叉熵等價於最小化觀測值和估計值的相對熵(relative entropy),即兩者機率分布的Kullback-Leibler散度: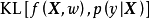 ,因此其是一個提供無偏估計的代理損失。交叉熵損失函式是表中使用最廣泛的代理損失,對應的分類器例子包括logistic回歸、人工神經網路和機率輸出的支持向量機。
,因此其是一個提供無偏估計的代理損失。交叉熵損失函式是表中使用最廣泛的代理損失,對應的分類器例子包括logistic回歸、人工神經網路和機率輸出的支持向量機。
指數損失函式是表中對錯誤分類施加最大懲罰的損失函式,因此其優勢是誤差梯度大,對應的極小值問題在使用梯度算法時求解速度快。使用指數損失的分類器通常為自適應提升算法(Adaptive Boosting, AdaBoost),AdaBoot利用指數損失易於計算的特點,構建多個可快速求解的“弱”分類器成員並按成員表現進行賦權和疊代,組合得到一個“強”分類器並輸出結果。
套用
案例一
某個工廠人員的產出,以每小時多少元來計算,而損失函式所顯示的,是產出以室內通風條件而改變的情形。廠內工作的每個人,都有自己的損失函式。為了簡化說明,假設每個人的損失函式均為一條拋物線,其底部一點代表產出值最大時的通風條件,把所有人員的損失函式進行疊加,公司整體的損失函式也必然是一條拋物線。如果通風條件偏離這個最佳水準,就會有額外損失發生。該拋物線與橫軸相切時,切點的左右各有一小段與橫軸幾近重合。也就是說,有最適點偏離一小短距離,損失小到可以忽略不計。因此,當室內通風條件稍稍偏離均衡點,發生的損失可以忽略不計。但是遠離均衡點時,總是有人必須支付這損失。如果我們能夠導出有具體數字的損失函式,我們就可以計算出最優均衡點,在均衡點中最適合的通風條件如何,以及達到要求的費用支出是多少。
案例二
以趕火車作為符合規格的例子。假設我們的時間價值為每分鐘n元,下圖左邊的斜線是損失線的斜率;早一分鐘到達月台,將讓我們損失n元,早兩分鐘到達損失2n元。另一方面,如果沒有趕上火車,我們的損失是M元。遲到半分鐘或遲到5分鐘損失一樣,損失函式直接由零跳到M。
當然問題也可複雜化,例如火車每天離站的時間也有變化,所以也可以畫出一個分配圖。火車到站時間三個標準差的界限可能是8秒。把問題這樣複雜化,對於我們了解和套用損失函式並沒有特別大的幫助,因此我們就說到這裡。 另一個例子,是參加星期日早上11點15分的禮拜時所碰到的停車問題。教堂的停車場最大負荷是停放50輛車子,但這些車位在10點50分左右仍然客滿,因為作完上一場禮拜的車主仍在喝咖啡。等他們一離開,這些空位馬上就會被排成長龍等待的車隊填滿。如果你想占到一個車位,不得不早早去排隊。那些晚到的人在這裡找不到車位,只能到街上去找,但實際上往往無功而返。所以,上策還是提早一點去等,承受等待的損失而能占到位置。
這項理論也可以套用到任何計畫的截止時間上。某人要求必須在截止日期前完成工作,萬一未能趕上這個時間,勢將使計畫延誤或出錯。為了能準時完成,可以擬定工作內容與步驟的綱要。把個步驟的截止日期 設 定一段期間要比設定為固定的從容,而且有時間作最後的修訂,可能把計畫做得更好。
