
均值池化(mean-pooling)即對局部接受域中的所有值求均值。
基本介紹
- 中文名:均值池化(
- 外文名:mean-pooling
- 本質:池化方法
- 別名:平均池化
介紹,例子,基於序的平均池化,
介紹
常用的池化方法有最大池化(max-pooling)和均值池化(mean-pooling)。根據相關理論,特徵提取的誤差主要來自兩個方面:
(1)鄰域大小受限造成的估計值方差增大;
(2)卷積層參數誤差造成估計均值的偏移。
一般來說,mean-pooling能減小第一種誤差,更多的保留圖像的背景信息,max-pooling能減小第二種誤差,更多的保留紋理信息。與mean-pooling近似,在局部意義上,則服從max-pooling的準則。
例子
假設pooling的窗大小是2x2, 在forward的時候啊,就是在前面卷積完的輸出上依次不重合的取2x2的窗平均,得到一個值就是當前mean pooling之後的值。backward的時候,把一個值分成四等分放到前面2x2的格子裡面就好了。如下:
forward: [1 3; 2 2] -> [2];
backward: [2] -> [0.5 0.5; 0.5 0.5].
基於序的平均池化
基於序的平均池化的動機是解決平均池化和最大池化容易損失大量有用信息的問題。最大池化將池化域內非最大激活值全部捨棄導致了嚴重的信息損失。同樣地,平均池化取池化域內的所有激活值進行平均,高的正的激活值可能和低的負的激活值相互抵消,從而導致判別性信息損失。基於序的平均池化方法解決這個問題通過取前
t 個數值最大的激活值進行平均。在池化域內,這前 t 個激活值的權重係數設為 1/t 其他的激活值的權重係數設為
0。因此,池化的結果可以通過下面的公式獲得:
t 個數值最大的激活值進行平均。在池化域內,這前 t 個激活值的權重係數設為 1/t 其他的激活值的權重係數設為
0。因此,池化的結果可以通過下面的公式獲得:
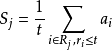
t 的取值不應太大,也不應太小,因為當 t =1時基於序的平均池化退化為最大池化,當t=n 時退化為平均池化.t 的取值應該能夠保證基於序的平均池化提供一個好的折中在最大池化和平均池化之間。不同的視覺任務,t 的取值是不同的,但是經驗發現當 t 取中值時一般取得滿意的結果。
基於序的池化方法將低的或者負的激活值排斥在外,僅僅使得具有高回響值的激活值參與平均操作。該方法能夠保留重要的信息,而將無用的信息捨棄,有利於深度卷積神經網路性能的提升。
