分散式異構型計算機系統(Distributed Heterogeneous System)由多個不同種 類的計算平台或套用子系統通過網路連線而成的計 算機系統。計算平台(簡稱早合)是指計算機的硬體系統和作業系統的組合。
例如,某一 分散式系統由3台微型計算機通過乙太網連線而 成。所有微型計算機都採用奔騰處理器晶片和 與IBM徽型計算機兼容的硬體體系結構,但用了3 種不同的作業系統:1台用Windows95,1台用WindowsNT,1台用Linux。這就是一個異構系統。
基本介紹
- 中文名:分散式異構系統
- 外文名:Distributed Heterogeneous System
- 縮寫:DHS
- 涉及學科:信息科學
- 實現:數據的共享和透明訪問
- 作業系統:Unix、Windows NT、 Linux
背景,異構資料庫系統,分散式系統,資料庫轉換,數據的透明訪問,動態任務調度策略,任務複製技術,每個任務僅有一個副版,每個任務有多個副版,Flex+Java,
背景
隨著計算機套用範圍的日益擴大,分散式異構系統(DHS DistributedHeterogeneous System)逐漸成為解決複雜套用問題的有效工具。DHS利用一組異構的計算機來協作完成套用任務,以期獲得最好的執行效果。DHS中的任務調度問題,對發揮系統的並行性能和保持負載平衡具有非常重要的意義。該問題已被證明是NP完全問題,無法在多項式時間內找到最優解,所以促使人們不懈地研究如何設計調度算法,用有限的代價獲得更好的解。目前常用的方法就是啟發式算法和隨機搜尋的近似方法。
異構資料庫系統
異構資料庫系統是相關的多個資料庫系統的集合,可以實現數據的共享和透明訪問,每個資料庫系統在加入異構資料庫系統之前本身就已經存在,擁有自己的DBMS。異構資料庫的各個組成部分具有自身的自治性,實現數據共享的同時,每個資料庫系統仍保有自己的套用特性、完整性控制和安全性控制。異構資料庫系統的異構性主要體現在以下幾個方面:
1、計算機體系結構的異構
各個參與的資料庫可以分別運行在大型機、小型機、工作站、PC或嵌入式系統中。
2、基礎作業系統的異構
各個資料庫系統的基礎作業系統可以是Unix、Windows NT、 Linux等。
3、DBMS本身的異構
可以是同為關係型資料庫系統的Oracle、 SQL Server等,也可以是不同數據模型的資料庫,如關係、模式、層次、網路、面向對象,函式型資料庫共同組成一個異構資料庫系統。
----異構資料庫系統的目標在於實現不同資料庫之間的數據信息資源、硬體設備資源和人力資源的合併和共享。其中關鍵的一點就是以局部資料庫模式為基礎,建立全局的數據模式或全局外視圖。這種全局模式對於建立高級的決策支持系統尤為重要。
----大型機構在許多地點都有分支機構,每個子機構的資料庫中都有著自己的信息數據,而決策制訂人員一般只關心巨觀的、為全局模式所描述的信息。建立在數據倉庫技術基礎上的異構資料庫全局模式的描述是一種好的解決方案。數據倉庫可以從異構資料庫系統中的多個資料庫中收集信息,並建立統一的全局模式,同時收集的數據還支持對歷史數據的訪問,用戶通過數據倉庫提供的統一的數據接口進行決策支持的查詢。
1、計算機體系結構的異構
各個參與的資料庫可以分別運行在大型機、小型機、工作站、PC或嵌入式系統中。
2、基礎作業系統的異構
各個資料庫系統的基礎作業系統可以是Unix、Windows NT、 Linux等。
3、DBMS本身的異構
可以是同為關係型資料庫系統的Oracle、 SQL Server等,也可以是不同數據模型的資料庫,如關係、模式、層次、網路、面向對象,函式型資料庫共同組成一個異構資料庫系統。
----異構資料庫系統的目標在於實現不同資料庫之間的數據信息資源、硬體設備資源和人力資源的合併和共享。其中關鍵的一點就是以局部資料庫模式為基礎,建立全局的數據模式或全局外視圖。這種全局模式對於建立高級的決策支持系統尤為重要。
----大型機構在許多地點都有分支機構,每個子機構的資料庫中都有著自己的信息數據,而決策制訂人員一般只關心巨觀的、為全局模式所描述的信息。建立在數據倉庫技術基礎上的異構資料庫全局模式的描述是一種好的解決方案。數據倉庫可以從異構資料庫系統中的多個資料庫中收集信息,並建立統一的全局模式,同時收集的數據還支持對歷史數據的訪問,用戶通過數據倉庫提供的統一的數據接口進行決策支持的查詢。
分散式系統
在一個分散式系統中,一組獨立的計算機展現給用戶的是一個統一的整體,就好像是一個系統似的。系統擁有多種通用的物理和邏輯資源,可以動態的分配任務,分散的物理和邏輯資源通過計算機網路實現信息交換。系統中存在一個以全局的方式管理計算機資源的分散式作業系統。通常,對用戶來說,分散式系統只有一個模型或范型。在作業系統之上有一層軟體中間件(middleware)負責實現這個模型。一個著名的分散式系統的例子是全球資訊網(World Wide Web),在全球資訊網中,所有的一切看起來就好像是一個文檔(Web頁面)一樣。
在計算機網路中,這種統一性、模型以及其中的軟體都不存在。用戶看到的是實際的機器,計算機網路並沒有使這些機器看起來是統一的。如果這些機器有不同的硬體或者不同的作業系統,那么,這些差異對於用戶來說都是完全可見的。如果一個用戶希望在一台遠程機器上運行一個程式,那么,他必須登入到遠程機器上,然後在那台機器上運行該程式。
他們的區別在於:分散式作業系統的設計思想和網路作業系統是不同的,這決定了他們在結構、工作方式和功能上也不同。網路作業系統要求網路用戶在使用網路資源時首先必須了解網路資源,網路用戶必須知道網路中各個計算機的功能與配置、軟體資源、網路檔案結構等情況,在網路中如果用戶要讀一個已分享檔案時,用戶必須知道這個檔案放在哪一台計算機的哪一個目錄下;分散式作業系統是以全局方式管理系統資源的,它可以為用戶任意調度網路資源,並且調度過程是“透明”的。當用戶提交一個作業時,分散式作業系統能夠根據需要在系統中選擇最合適的處理器,將用戶的作業提交到該處理程式,在處理器完成作業後,將結果傳給用戶。在這個過程中,用戶並不會意識到有多個處理器的存在,這個系統就像是一個處理器一樣。
資料庫轉換
----對於異構資料庫系統,實現數據共享應當達到兩點:一是實現資料庫轉換;二是實現數據的透明訪問。由華中科技大學開發的,擁有自主著作權的商品化資料庫管理系統DM3系統,通過所提供的資料庫轉換工具和API接口實現了這兩點。
----DM3提供了資料庫轉換工具,可以將一種資料庫系統中定義的模型轉化為另一種資料庫中的模型,然後根據需要再裝入數據,這時用戶就可以利用自己熟悉的資料庫系統和熟悉的查詢語言,實現數據共享的目標。資料庫轉換工具首先進行類型轉換,訪問源資料庫系統,將源資料庫的數據定義模型轉換為目標資料庫的數據定義模型,然後進行數據重組,即將源資料庫系統中的數據裝入到目的資料庫中。
----在轉換的過程中,有時要想實現嚴格的等價轉換是比較困難的。首先要確定兩種模型中所存在的各種語法和語義上的衝突,這些衝突可能包括:
命名衝突:即源模型中的標識符可能是目的模型中的保留字,這時就需要重新命名。
格式衝突:同一種數據類型可能有不同的表示方法和語義差異,這時需要定義兩種模型之間的變換函式。
結構衝突:如果兩種資料庫系統之間的數據定義模型不同,如分別為關係模型和層次模型,那么需要重新定義實體屬性和聯繫,以防止屬性或聯繫信息的丟失。
----總之,在進行數據轉換後,一方面源資料庫模式中所有需要共享的信息都轉換到目的資料庫中,另一方面這種轉換又不能包含冗餘的關聯信息。
----資料庫轉換工具可以實現不同資料庫系統之間的數據模型轉換,需要進一步研究的問題是:如果資料庫轉換同時進行數據定義模式轉換和數據轉換,就可能引起同一數據集合在異構資料庫系統中存在多個副本,因此需要引入新的訪問控制機制。在保證各個參與資料庫自治,維護其完整性、安全性的基礎上,對於異構資料庫系統提供全局的訪問控制、並發機制和安全控制。
----如果資料庫轉換隻進行數據定義轉換,不產生數據的副本,那么在新的目的資料庫定義模型的框架下訪問數據,實現上仍是對源資料庫系統中數據的訪問。這時利用新的資料庫系統中的數據處理語言實現的事務,不能直接訪問源資料庫,必須進行事務級的翻譯才可以執行。
數據的透明訪問
----在異構數據系統中實現了數據的透明訪問,用戶就可以將異構分散式資料庫系統看成普通的分散式資料庫系統,用自己熟悉的數據處理語言去訪問資料庫,如同訪問一個資料庫系統一樣。但目前還沒有一種廣泛使用的數據定義模型和數據查詢語言,實現數據的透明訪問可以採用多對一轉換、雙向的中間件等技術。開放式資料庫互連(Open DataBaseconnectivity,簡稱ODBC)是一種用來在相關或不相關的資料庫管理系統中存取數據的標準應用程式接口(API)。ODBC為應用程式提供了一套高層調用接口規範和基於動態程式庫的運行支持環境。目前,常用的資料庫套用開發的前端工具如Power Builder、 Delphi等都通過開放資料庫互聯(ODBC)接口來連線各種資料庫系統。而多數資料庫管理系統(如:Oracle、Sybase、SQL Server等)都提供了相應的ODBC驅動程式,使資料庫系統具有很好的開放性。ODBC接口的最大優點是其互操作能力,理想情況下,每個驅動程式和數據源應支持完全相同的ODBC函式調用和SQL語句,使得ODBC應用程式可以操作所有的資料庫系統。然而,實際上不同的資料庫對SQL語法的支持程度各不相同,因此,ODBC規範定義了驅動程式的一致性級別,ODBC API的一致性確定了應用程式所能調用的ODBC函式種類,ODBC 2.0規定了三個級別的函式,目前 DM3 ODBC API支持 ODBC 2.0規範中第二級擴展的所有函式。
----隨著Internet套用的不斷普及,Internet的異構分散式信息系統正在迅速發展,Java以其平台無關性、移植性強,安全性高、穩定性好、分散式、面向對象等優點而成為Internet套用開發的首選語言。在Internet環境下,實現基於異種系統平台的資料庫套用,必須提供一個獨立於特定資料庫管理系統的統一編程界面和一個基於 SQL的通用的資料庫訪問方法。Java與資料庫接口規範JDBC(Java Database Connectivity)是支持基本SQL功能的一個通用的應用程式編程接口,它在不同的資料庫功能模組的層次上提供了一個統一的用戶界面,為對異構資料庫進行直接的Web訪問提供了新的解決方案。 JDBC已被越來越多的資料庫廠商、連線廠商、Internet服務廠商及應用程式編制者所支持。
動態任務調度策略
靜態調度策略在調度前,並行程式的各子任務執行位置己經確定,而且經常用於任務關係比較確定的情況,但實際的並行程式較難滿足此限制,並在執行中存在眾多不確定因素,如:
1.並行程式任務中的循環次數事先不能確定。
2.條件分支語句到底執行哪個分支,在程式執行前不能完全了解。
3.每個任務的負載大小事先不能確定。
4.任務間的數據通訊量大小只有在運行時才能確定。
而且在結點機的負載波動較大時,應考慮採用動態負載平衡的任務調度策略。在分散式系統中,動態負載平衡就是系統根據當前的系統狀態與負載分布的情況,對各個結點上的工作負載進行動態的調整,使待分配的或者已分配給重載結點的任務,通過通訊設備遷移到輕載結點上去,從而提高系統資源的利用率,減少任務的平均回響時間。
動態任務分配策略具有超過靜態調度策略的執行潛力,能夠相互交換系統的狀態信息決定系統負載的分配,能夠適應系統負載變化情況,比靜態調度策略更靈活、有效。動態調度策略利用系統狀態的短期波動來提高性能,由於它必須收集、儲存並分析狀態信息,因此動態調度策略會產生比靜態調度策略更多的系統開銷,但這種開銷常常可以被抵消掉。
任務複製技術
在異構分散式系統中,任務複製技術是實現容錯的主要手段,最具代表性的主/副版技術(Primary/Backup Copy,P/B)廣泛套用於容錯調度方法。它通過在備份處理器上執行備份任務來實現容錯。
P/B複製技術有3種執行方式:主動複製方式(ActiveBackup Copy、被動複製方式(Passive BackupCopy)和混合複製方式(P/B Overlapping BackupCopy)。目前學術界對DAU任務容錯調度的研究也都是基於任務複製機制,針對副版數複製數量來區分,主要有2種複製方式.
每個任務僅有一個副版
DAU可靠性代價驅動的eFRCD(efficient Fault tolerant Reliability Cost Driven)算法,該算法對DAU中的每一個任務都有一個分配在不同處理器上的副版任務。為了提高性能,對於主版不在同一個處理器上的多個任務,系統允許在同一個處理器上的這些任務的副版可以重疊。然而,這種方法必須假設這些任務之間是相互獨立的,不能滿足DAU中有優先權約束任務的需要,因此在eFRCD算法基礎上,又提出了改進的eFRD(efficient Fault tolerant Reliability Driven)算法,該算法採用主副版重疊機制,即允許任務的副版與此任務的所有後繼任務的主版重疊,可以進一步降低調度長度。在eFRD算法的基礎上提出了基於最早完成時間的最小複製開銷的MRC-ECT(Minimum Replication Cost with EarlyCompletion Time)算法和基於最小複製開銷的最小完成時間的MCT-LRC(Minimum Completion Timewith Less Replication Cost)算法分別對DAU中的非獨立任務和獨立任務進行容錯調度。
首先,上述研究針對可靠性問題,假設某一個時刻最多只有一個處理器出現故障,且在下個故障出現時,前一個故障己經排除,假設較為理想導致實用性不強。同時也只考慮DAU的可調度性,沒有考慮可靠性目標。給出可靠性目標的定義,即系統任務集裡的每個任務都有。個副版,一個任務成功分配的條件是該任務的。個副版分配到不同的處理器上,且沒有導致這些處理器的利用率超過1,在滿足任務副版時間約束和系統高可靠性條件的基礎上,最大化成功的分配任務。
其次,上述算法都是採用被動複製方式,只有當主版任務調度失敗後才能啟動副版任務,被動複製在主版任務失效時,需要選擇一個新副版任務恢復到失效前狀態,造成失效恢復時間較長.因此從截止期限和失效恢復時間考慮,主動複製優於被動複製叫。主動複製能夠在運行失效時直接禁止失效的任務版,失效恢復時間幾乎接近於零,調度長度也相對較短。
每個任務有多個副版
提出基於主動複製的FTSA ( FaultTolerant Scheduling Algorithm)算法,此算法是經典的非任務複製的DAU調度算法HEFT( Heterogeneous Earliest Finish Time)的擴展。FTSA容忍ε個錯誤的發生,並且有ε+1個版本允許在不同的處理器上,但FTSA算法每次只選擇一個優先權最高的就緒任務調度。提出了同樣基於主動複製的CAFT(Contention Awareness and Fault Tolerant)算法,與FTSA算法每次只選擇一個優先權最高的就緒任務不同,CAFT選擇一組就緒任務,在同一決策過程中分配其所有副版到相應的處理器,這樣能夠產生更好的負載均衡.但是FTSA和CAFT算法為了使系統能夠達到容忍多個故障,採用了盲目的複製策略,即對於每個任務需要複製的版本個數,並沒有精確的量化,而是盲目地使每個任務擁有ε+1個副版,容忍系統中任務可能存在的ε個故障。雖提高了系統的可靠性卻易造成任務冗餘過高,使得調度過程中既付出了昂貴的計算資源,又造成調度長度過長而可能錯過任務的截止期限。盲目的複製策略套用到多個DAU,將造成更加劇了系統的冗餘程度過高。
針對主動複製採用ε+1個副版容忍ε個故障的情況,擁有更多的副版並不意味更高的可靠性。其提出的MaxRe算法針對不同的任務,基於可靠性目標而採用不同的副版次數,在滿足系統的可靠性目標的前提下,能夠最小化資源的使用。但是該算法認為每個任務的可靠性目標為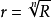 ,其中R為DAG的可靠性需求,n為任務個數,但是由於DAU中的任務存在優先權約束,對於有前驅的任務,需要考慮其直接前驅任務的影響,不能依靠簡單的開方就能斷定。
,其中R為DAG的可靠性需求,n為任務個數,但是由於DAU中的任務存在優先權約束,對於有前驅的任務,需要考慮其直接前驅任務的影響,不能依靠簡單的開方就能斷定。
Flex+Java
企業的套用系統主要分為三層:
展現層
領域層(業務層)
數據源層
Flex+Java企業套用中,“展線層”邏輯完全運行在客戶端的Flash虛擬機中,而“領域層”和“數據訪問層”邏輯則運行在伺服器端的Java虛擬機中,客戶端系統與服務端系統完全用不同的語言實現,因此系統是異構的。同時,客戶端代碼運行在客戶端的ActionScript虛擬機中,而伺服器的代碼則運行在伺服器上的Java虛擬集中,因此,系統又是分散式的。
這與傳統Web套用完全不同,傳統(JSP/Servlet)套用中所有代碼,包括業務邏輯代碼和生成人機界面的代碼都是在伺服器Java虛擬機中執行,如圖:
 伺服器端Java虛擬機
伺服器端Java虛擬機 伺服器端Java虛擬機
伺服器端Java虛擬機Flex+Java與傳統jsp/servlet/struts系統區別是:
使用Flex+java開發的B/S套用系統中,B系統(客戶端系統)和S系統(伺服器端系統)完全分離。B系統負責“展示層”邏輯,而 s 系統主要負責“領域層”和“數據源層”邏輯。因此,flex+java所開發的系統是異構的分散式系統。
