隨著信息化建設的快速發展,信息化與各行各業的融合更加緊密,信息系統在各業務領域發揮的作用越來越明顯。錯誤檢測系統是保障信息系統持續安全穩定運行的重要手段,防患於未然,避免重大損失。目前,文本檢測、語音檢測、安全檢測等錯誤檢測技術被廣泛套用到醫療、金融等行業的信息化建設當中。
基本介紹
- 中文名:錯誤檢測系統
- 外文名:Error Detecting System
- 領域:計算機設計
- 分類:信息科學
- 套用:醫學、金融、計算機等
- 相關:文本檢測、語音檢測等
概述,文本檢測,命名實體識別,中文分詞技術,語音檢測,音素髮音質量,字的發音質量,WEB錯誤檢測,PBL方法,相關定義,數據集初始化,錯誤檢測框架,
概述
錯誤檢測系統是保障信息系統持續安全穩定運行的重要手段,將文本檢測、語音檢測、安全檢測等錯誤檢測技術被廣泛套用到醫療、金融等行業的信息化建設當中,提升系統持續安全穩定運行的能力。
文本檢測
命名實體識別
命名實體(Named Entity)是語料中關鍵的辭彙單位,承載了文本中的絕大部分的主要信息。最初,命名實體被定義為文本中包含人名、地名以及機構名的實體,例如在句子“[國際奧委會]主席[巴赫]訪問[中國]”中,“國際奧委會”是機構名,“巴赫”是人名,“中國”是地名,通過這些命名實體就能獲取到句子的主要內容。隨著搜尋引擎、機器翻譯、數據挖掘等技術的不斷發展,對於命名實體也有了更加寬泛的定義。而在醫學臨床以及生物相關領域,許多專有名詞也陸續被學者們定義為命名實體,例如蛋白質名、基因名、疾病名等。在當今的自然語言處理研究中,普遍將命名實體分為名詞、數字和時間這三種類型。
命名實體識別(Named Entity Recognition,NER)就是指識別文本中被定義為命名實體的專有名詞,並加以歸類。即命名實體識別的過程分為兩個步驟,一是確定實體在文本中的語料邊際;二是確定該實體的類型。由於數字類實體和時間類實體通常以時間、日期、貨幣、百分比等形式出現,具有固定的組成模式,通過正則表達式進行匹配便可以簡單識別。所以,命名實體識別的主要困難是對名詞類實體的準確識別,尤其是特定領域的專有名詞。
命名實體識別作為自然語言處理研究的一個基本任務,在各類語言的自由文本中均有著廣泛的研究。其中英文命名實體識別起步較早,取得了較好的研究成果,而中文命名實體識別的研究仍處在不太成熟的階段。究其原因,除了發展較晚之外,主要有以下幾點:
- 中文不像英文中單詞與單詞之間自然存在著空格作為分隔設定,中文可以單字成詞也可以多字組詞,較於英文而言,對於實體邊際的確定難度十分高;
- 中文的語言特性更為靈活多變,縮略詞的組成規律和表現形式十分繁雜,很難形成既定的規則,而命名實體往往以縮略詞的形式存在;
- 相較於英文,中文缺少對於詞征的顯性標誌,比如英文中的專有名詞通常以首字母大寫或者大寫全拼表示,而中文並沒有這種特徵。
因此,由於中文的這些特性,中文命名實體識別在進行識別操作前,往往需要對文本進行分詞預處理,從而輔助實體邊際的確定。
中文分詞技術
目前常用的中文自動分詞技術按照分詞的策略可以分為基於規則和基於統計兩大類。而近幾年,為了提高對於未登錄詞識別的性能,基於宇的中文分詞技術也逐漸發展起來,所以如若按照分詞的最小考量粒度來分類,中文自動分詞技術還可以分為基於詞和基於字兩大類。
1. 基於規則和字典的匹配分詞
該方法通過構詞規則以及足夠龐大的分詞字典作為知識來源,按照既定的規則對中文字串進行匹配分詞。如若在字典中匹配到了一個辭彙,那么就將被匹配項作為一個詞進行切割。顯然,基於規則的分詞方法是基於詞為最小考量粒度的方法。以反向最短匹配法為例,該種方法從文本末尾開始逆向切割分詞,並通過截取最小長度來匹配字典,如果匹配失敗再將匹配長度加l,如此往復,直至匹配項與字典中詞條吻合。如果待匹配長度已經超過字典的最長詞條長度或者匹配索引已經到達了文本首字元處,仍未匹配到詞條,那么就將此次匹配的尾字作為單字詞收錄。可以發現基於字典和規則的匹配方法,實現難度較低並且操作簡單,只要保證字典的權威性和數據容量足夠大,就能完成詞語的切割。但這種機械切割的方式很容易造成錯誤,譬如如果文本中存在“中華人民共和國”這個辭彙,那么按照反向最短匹配算法進行分詞處理後,文本中的“中華人民共和國”將被破壞為“中華”、“人名”、“共和國”3個零散的詞語。而想要將諸如此類的構詞形態納入規則中去考慮,是十分繁瑣的。
2. 基於統計學習的機器分詞
基於統計學習的方法根據其是否使用事先編制的詞典,可以分為基於字和基於詞兩種方法。基於字的分詞方法,實際上是一種構詞方法,即把分詞過程看作是把句子中的每一個單字組成詞的過程。主要思路是通過對訓練語料進行字標註,統計得到各個字的標註特性組合的頻次以及緊密程度,以此反映字與字之間能否成詞的可信度。這類方法經常會誤識別一些共現頻度高、但不是詞的常用字組,因此對常用詞的識別精度較差,但是對於未登錄詞的識別性能卻顯著優於其他方法。
語音檢測
錯誤檢測系統在語音檢測技術上的運用主要用於計算機輔助語言學習(Computer Assistant Language Learning,CALL)中的發音錯誤檢測。現在的發音錯誤檢測方法的研究主要有兩大類。一類是基於語音學知識以及區分性特徵的方法,另一類是基於統計語音識別框架的發音檢錯方法,在這兩類方法中,基於統計語音識別框架的檢測方法處於主流位置。
音素髮音質量
HMM統計模型可以用來表示每個音素的標準發音,對數後驗機率(Log-Posterior Probability,LPP)用於測試音素的發音質量。由於說話人特性的不同和信道的變化會導致輸入信號的頻譜不匹配,而該參數受頻譜變化的影響較小,能更加集中的反映發音質量。
在實際的套用中,由於聲學得分的動態範圍非常大,會導致LPP值僅僅分布在幾個很窄的範圍內。因此,需要把聲學得分做比例化處理,從而使得分具有可操作性。通過引入一個合適的比例化因子a,使得後驗機率在0和1之間的分布更加均勻,經過比例化的LPP值在本文中稱為比例化對數後驗機率(Scaled Log-Posterior Probability,SLPP)。在一個基於HMM的語音識別器中,給定某個音素的觀察矢量O和它對應的標註qi,該音素的SLPP值可計算如下:

其中L是維特比(Viterbi)解碼產生的格線(Lattice)中的路徑總數,K是其中含有音素qi的路徑總數, 是格線中第l條路徑的似然比,
是格線中第l條路徑的似然比, 是格線中包含有qi的第k條路徑的似然比,
是格線中包含有qi的第k條路徑的似然比, 是音素qi的先驗機率。
是音素qi的先驗機率。
字的發音質量
為了檢測國語的字發音錯誤,首先要獲得每個音素的SLPP值。然後,每個字的得分就可以用其音素的SLPP值來做加權平均。由於國語每個字一般都由聲母和韻母組成,則字的發音質量得分可用下式表示:
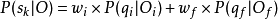
其中叫wi和wf是聲母qi和韻母qf的權重。
WEB錯誤檢測
WEB系統自動化錯誤檢測系統改變了傳統WEB功能選單落後的人工巡檢方式,,提高系統巡檢工作效率,避免出現漏巡漏檢的情況,促進運維資源最佳化分配;同時實現功能選單巡檢結果報表分析,為系統性能分析提供數據支持。
其實現步驟如下:
- 基礎環境變數自定義,變數包括套用系統及資料庫服務兩個方面。套用系統方面主要有訪問地址、連線埠、用戶登錄帳號、用戶密碼(密文);資料庫服務方面主要有資料庫地址、帳號、密碼、查詢功能選單名與功能選單URL的SQL語句(資料庫相關變數只需在選擇直連資料庫方式獲取功能選單信息時配置,另一種獲取功能選單信息的方式是通過CSV配置檔案);
- 創建資料庫連線。第三方開源工具內置了JDBC驅動,只需要根據變數信息添加連線字元串即可完成資料庫連線配置,正常執行資料庫查詢語句;
- 創建JDBC Request查詢功能選單。通過JDBC資料庫連線,執行事先定義好的資料庫SQL語句,查詢被檢測信息系統的所有功能選單,查詢結果包括選單名稱以及與之對應URL;
- 創建HTTP請求採樣器。採樣器將記錄用戶登錄行為,獲取訪問過程中使用的會話ID、密碼(密文),為後續系統選單的檢測工作提供必要的登入信息;
- 創建HTTP請求採樣器。採樣器負責模擬用戶訪問選單的行為,根據所有功能選單的uRL逐一發起請求進行頁面訪問,然後記錄每個功能選單的訪問結果,分析每一次URL訪問是否正常;
- 創建斷言規則。Jmeter將HTTP請求採樣器的結果與斷言規則進行比對,針對頁面的返回值進行斷言,通過檢測的頁面顯示正常,沒有通過檢測則為異常,正常的結果代碼顯示為200,異常的結果代碼有500、404、403等;
- 創建“察看結果樹”。結果樹主要方便閱讀分析,可快速瀏覽檢測過程中錯誤頁面與正確頁面的回響情況,展現各功能選單的詳細訪問路徑和請求信息。
PBL方法
入侵容忍系統(Intrusion Tolerance System,ITS)是第3代安全技術——信息生存技術中的核心內容,它是一種參考生物免疫原理的抵抗入侵的終極技術,作為套用系統的最後一道安全防線,即使在威脅性的環境下也要確保系統能動態安全退化,提供全部或降級的服務。錯誤檢測(Error Detection ,ED)是保障ITS無邊界退化的重要環節,其目標在於限制錯誤、避免蔓延以及確保在發現錯誤後能及時觸發錯誤恢復機制和故障處理機制。
PBL正是一種面向容侵系統的並行錯誤檢測方法。
相關定義
定義1. 貝葉斯格線(Bayesian Network)是一種將貝葉斯機率和有向無環圖的網路拓撲結構有機結合的表示模型,描述了元組數據項及元組和元組之間的相互依賴關係。和一個貝葉斯網路結構相同的無向無環圖稱為該貝葉斯網路的網架。
PBL方法中,一個貝葉斯網路可表示為(G, p),其中G-(V, E)是有向無環圖,V是G的節點集,表示可描述容侵系統錯誤狀態的系統事件集合,E是G的邊,表示V中節點之間的機率聯繫。
定義2. 節點x1, x2∈V,x1和x2的條件互信息可表示為

其中S⊂V,若I(x1, x2))小於某一指定的閾值ξ,則稱x1和x2條件獨立。
數據集初始化
PBL方法從3個方面建立錯誤檢測的模式資料庫:
- 因系統軟硬體原因導致的錯誤,諸如非法地址、強制性指令、數據類型不匹配、事件延遲等;
- 因外界入侵引起的系統錯誤;
- 相同的系統缺陷經不同複製可能引起不同的錯誤;
故而有必要對不同的拷貝對照檢查,建立相應錯誤模式。
首先將訓練數據轉換到時序資料庫,然後按時序順序依次計算兩個元組之間的互信息,並由大到小排序,最後依據不產生環路的原則按順序依次添加邊,直到添加n-1條邊為止;然後將貝葉斯網路從根節點開始向下延伸,將複雜的貝葉斯網路拆分成若干個只有一個根節點的有向無環的圖,以簡化模式資料庫。
錯誤檢測框架
PBL並行錯誤檢測框架如圖1所示。其基本思想是: 圖1. PBL錯誤檢測框架
圖1. PBL錯誤檢測框架
圖1. PBL錯誤檢測框架1. 設有處理器P1, P2, ..., Pn,各處理器在本地採集系統數據,再在這些數據集上通過LBL(local Bayesian learning)引擎構建本地貝葉斯網路(local Bayesian networks ,LBN);2. 在每個處理器上,生成的LBN 和本地錯誤模式庫(local error database ,LED)匹配,如果匹配則表示是本地系統錯誤;不匹配也不能表明沒有錯誤發生,因為有可能是全局錯誤,故需將LBN 傳送到全局共享區(Share )中做進一步判斷;
3. Share 通過SDC(share data collection )機制選擇性接受P1,P2,...,Pn傳送來的數據,形成Share數據集;
4. 在Share 數據集上通過GBL(global Bayesian learni ng )引擎構建全局貝葉斯網路(global Bayesiannet Works ,GBN);
5.生成的GBN 和全局的錯誤模式庫(global error database ,GED)匹配,如果匹配則表示是全局系統錯誤,不匹配則表示沒有錯誤發生。
