基本介紹
- 中文名:鄰里成分分析
- 外文名:Neighbourhood components analysis
- 領域:人工智慧
定義,解釋說明,留一分類,解決方法,目標函式最佳化,歷史和背景,相關研究和理論,
定義
鄰里成分分析是一種距離度量學習方法,其目的在於通過在訓練集上學習得到一個線性空間轉移矩陣,在新的轉換空間中最大化平均留一(LOO)分類效果。該算法的關鍵是與空間轉換矩陣相關的的一個正定矩陣A,該矩陣A可以通過定義A的一個可微的目標函式並利用疊代法(如共軛梯度法、共軛梯度下降法等)求解得到。該算法的好處之一是類別數K可以用一個函式f(確定標量常數)來定義。因此該算法可以用來解決模型選擇的問題。
解釋說明
為了定義轉換矩陣A,我們首先定義一個在新的轉換矩陣中表示分類準確率的目標函式,並且嘗試確定A使得這個目標函式最大化。
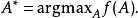
留一分類
對一個單一的數據點進行類別預測時,我們需要考慮有一種給定的距離度量確定的K個最近鄰居,根據k個近鄰的類別標籤投票得到該樣本的類別。這就是留一(Loo)分類算法。但是對所有數據集進行一個線性空間變換之後,新空間中的同一樣本的最近鄰居集可能跟原空間的最近鄰居集有很大差別。特別的,為了平滑A中元素的變化,我們可以使該樣本的最近鄰居集離散化,也就是說任意一個基於一個點的最近鄰居集的目標函式f都是離散的,因此也是不連續的。
解決方法
我們可以用一種受隨機梯度下降法算法的啟示得到的方法解決該問題。在新的轉換空間中,我們並不是對每個樣本點用留一分類方法求取k個最近鄰居,而是在新空間中考慮整個數據集作為隨機最近鄰居。我們用一個平方歐氏距離函式來定義在新的轉換空間中的留一數據點與其他數據的距離,該函式定義如下:
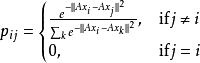
輸入點i的分類準確率是與其相鄰的最近鄰居集 的分類準確率:
的分類準確率: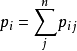 其中
其中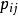 是j是i的最近鄰居的機率。 定義用全局數據集作為隨機最近鄰的留一分類方法確定的目標函式如下:
是j是i的最近鄰居的機率。 定義用全局數據集作為隨機最近鄰的留一分類方法確定的目標函式如下:

由隨機近鄰理論知,與單一樣本點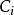 的同類別的在隨機近鄰域樣本點j可以表示為:
的同類別的在隨機近鄰域樣本點j可以表示為:

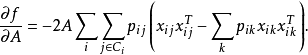
這裡用到了連續梯度下降算法。
目標函式最佳化
最大化函式f(.)相當於最小化預測的類分布和真正的類分布之間的差距,即使兩者更接近。故目標函式和梯度可以重新寫作:
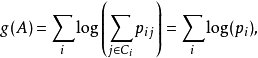
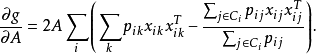
在實際套用中運用此方法得到最佳化的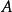 與之前的方法得到的有相似的預測結果。
與之前的方法得到的有相似的預測結果。
歷史和背景
鄰里成分分析是由Jacob Goldberger, Sam Roweis, Ruslan Salakhudinov和Geoff Hinton 等人在2004年在多倫多大學計算機系創建的。
相關研究和理論
- Cluster analysis
- K-Nearest Neighbours
- Spectral clustering
