
聲學模型是語音識別系統中最為重要的部分之一,目前的主流系統多採用隱馬爾科夫模型進行建模。 隱馬爾可夫模型的概念是一個離散時域有限狀態自動機,隱馬爾可夫模型HMM是指這一馬爾可夫模型的內部狀態外界不可見,外界只能看到各個時刻的輸出值。
對語音識別系統,輸出值通常就是從各個幀計算而得的聲學特徵。用HMM刻畫語音信號需作出兩個假設,一是內部狀態的轉移只與上一狀態有關,另一是輸出值只與當前狀態(或當前的狀態轉移)有關,這兩個假設大大降低了模型的複雜度。HMM的打分、解碼和訓練相應的算法是前向算法、Viterbi算法和前向後向算法。
基本介紹
- 中文名:聲學模型
- 外文名:Acoustic model,
- 組成:語音識別系統
- 模型:隱馬爾科夫模型
- 特點:多維的向量
輸出機率,拓撲結構,聚類方法,參數估計,
輸出機率
聲學模型的輸入是由特徵提取模組提取的特徵。一般來說,這些特徵是多維的向量,並且其取值可以是離散或連續的。早期的聲學模型常常採用矢量聚類(Vector Quantification)的方法,將信號直接映射到某個碼本k,而後再計算某個模型j輸出該碼本的機率bj(k)。但是這一方法是比較粗糙的,其性能受到VQ算法的極大影響,如果VQ本身性能就很差,聲學模型的估計就會很不準確。因此,對於連續取值的特徵應當採用連續的機率分布。由於語音信號特徵的分布並不能用簡單的機率分布,例如高斯分布等來直接描述,故而常用混合高斯模型或混合拉普拉斯模型等方法對語音信號的分布進行擬合。在此,混合高斯分布可以表示為若干高斯分量Gi的加權組合。即:

其中Gi(x)是均值為μi方差為σi的高斯分布。從數學角度看,當i趨向於無窮時,任何連續分布都可以用混合高斯模型來逼近。但是,高斯混合模型也存在著問題,那就是其計算量偏大。假設對於一個包含n個混合分量的混合高斯模型,其維度為m維,那么至少要進行 次運算才能得到結果,如果有i個模型需要計算,那么時間複雜度就是O(mnk)。相比之下,離散HMM就相對簡單,只需要進行一次VQ,再進行i次查表操作,就能夠計算所有模型的機率值。因此,也出現了將二者結合起來的半連續隱馬模型。其思路是輸出機率不僅僅由bj(k)來決定,還乘上了VQ的機率,亦即該信號屬於次碼本的機率。
次運算才能得到結果,如果有i個模型需要計算,那么時間複雜度就是O(mnk)。相比之下,離散HMM就相對簡單,只需要進行一次VQ,再進行i次查表操作,就能夠計算所有模型的機率值。因此,也出現了將二者結合起來的半連續隱馬模型。其思路是輸出機率不僅僅由bj(k)來決定,還乘上了VQ的機率,亦即該信號屬於次碼本的機率。
從精確度上看,連續隱馬模型要優於半連續隱馬模型,而半連續隱馬模型又優於離散隱馬模型。從算法複雜度上來看則正好相反。
高斯混合模型(Gaussian Mixture Model, GMM)是語音信號處理中的一種常用的統計模型,該模型的一個基本理論前提是只要高斯混合的數目足夠多,一個任意的分布就可以在任意的精度下用這些高斯混合的加權平均來逼近。一個包含M個分量的高斯混合分布的機率密度函式是M個高斯機率密度分布函式的加權組合,定義為:

其中的x是D維隨機矢量, ,M為M個機率密度函式分量,
,M為M個機率密度函式分量, ,M為各個機率密度函式分量的權重。在上式中,每個機率密度函式分量pi(x)都服從D維高斯分布,即
,M為各個機率密度函式分量的權重。在上式中,每個機率密度函式分量pi(x)都服從D維高斯分布,即
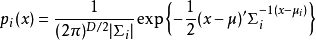
其中,μi表示該高斯分量的均值,Σi表示該高斯分量的協方差矩陣。另外,為了滿足機率密度函式分布的要求,上式中各個機率密度函式分量的權重必須滿足 的要求。
的要求。
在高斯混合模型中,每一個高斯機率密度函式分量pi(x)都可以由其權重wi、均值μi和協方差矩陣Σi來描述。這樣,一個完整的M分量混合的高斯分 布就可以由以下的三元組集合來表示:
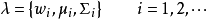
GMM模型的主要問題為訓練問題,亦即參數估計問題數估計,使得GMM模型和訓練數據之間達到最佳的匹配程度。GMM的參數估 計方法有多種方法,其中套用最廣泛的是基於最大似然準則(Maximum Likelihood Estimation, MLE)的方法。
對於一段給定的訓練語音特徵序列 ,GMM模型的似然度定義為:
,GMM模型的似然度定義為:

最大似然估計的主要思想就是要找到使得GMM模型對於訓練語料的似然度最大的模型參數λ。同HMM的訓練類似,GMM訓練也可以通過EM進行訓練,其模型參數更新公式為:



其中p(i | xt,λ)表示xt屬於第i個高斯分量的後驗機率。而 分表表示上一步疊代中模型的 權重、均值、協方差矩陣,而
分表表示上一步疊代中模型的 權重、均值、協方差矩陣,而 則是更新後的對應參數。p(i | xt,λ)的定義為:
則是更新後的對應參數。p(i | xt,λ)的定義為:

如果隨機矢量各維間的是獨立的,那么可以採用對角協方差陣,亦即僅估計方差。這種方法能夠極大減少模型參數,讓模型訓練更加充分。同時,需要注意的是,在某些情況下,對角協方差陣可能會出現非常小的方差值,從而使得協方差陣奇異。因此在訓練對角協方差陣的時候必須採用最小方差約束。亦即當新估計出的某維方差 小於設定σmin時,讓
小於設定σmin時,讓 等於σmin。
等於σmin。
在聲學模型訓練中常用GMM為狀態輸出機率建模,同時GMM也常用於其他聲音分類任務中,例如聲音分割與分類,說話人識別等。
拓撲結構
由於語音的時序性,隱馬模型的拓撲結構一般都取為自左向右的結構。一般每個狀態都包括自跳轉弧。是否允許跨狀態 跳轉則沒有一個定論。
下圖是典型的模型拓撲結構示意圖。
狀態個數的選擇對於系統性能的影響是很大的。
建模單元選擇
聲學模型的建模單元的選擇需要考慮三方面的因素。其一是該單元的可訓練性,亦即是否能夠得到足夠的語料對每個單元進行訓練,以及訓練所需要的時間長短是否可接受。其二是該單元的可推廣性,當語音識別系統所針對的辭彙集 發生變化時,原有建模單元是否能夠不加修改的滿足新的辭彙集
發生變化時,原有建模單元是否能夠不加修改的滿足新的辭彙集 。最後還需要考慮建模的精確性。
。最後還需要考慮建模的精確性。
根據時間尺度的長短,建模單元可以選擇為句子,短語,詞,音節,音子乃至更小的半音子。一般可以認為有這樣的原則, 時間尺度越短的建模單元,其可訓練性及推廣性就越強,而時間尺度越長的單元,其精確性就越強。同時,可以看出,句子、 短語、詞三個概念是語言學上的概念,而音節、音子則是語音學上的概念,一般來說,如果聲學模型所針對的套用環境不是 確定辭彙量的系統,那么採用語言學的概念的建模單元是不具備推廣性的。
為了將協同發音現象(Coarticulation)融入建模中,上下文相關的建模單元(Context Dependent Modeling Units, CD uinits)是一個很好的選擇。其思路是,對於某個音子ah,根據上下文的不同將其拆分成不同的建模單元。例如,用b-ah+d表示ah在b之後,d之前發音的具體實現。上下文的選擇方法有很多,最常見的是三音子建模單元,也就是考慮左上文右下文各一個音子,加上中心音子形成三音子對。
上下文相關建模大大提高了建模的準確性,但是同時也使得模型數量急劇膨脹,使得模型的可訓練性大大降低。為了解決這一 問題,就需要引入某些聚類算法來減少模型中需要訓練的參數。
聚類方法
為了解決模型參數過多的問題,可以使用某些聚類方法來減小模型中的參數數量,提高模型的可訓練性。聚類可以在模型層次, 狀態層次乃至混合高斯模型中每個混合的層次進行。可以將半連續隱馬模型看作進行高斯混合進行聚類後的連續隱馬模型。目前 套用最多的方法是對狀態聚類的方法。其思路是,根據狀態間混合高斯模型機率輸出的相似性,將輸出機率接近的狀態聚合在 一起,以便對其的訓練更加充分。聚類的方法有基於規則的方法和數據驅動方法兩類。
聚類後的狀態被稱為Senone,每個Senone都是完整獨立的高斯混合模型,它也是解碼過程中的最基本單元。
參數估計
傳統上,參數估計使用的方法為Baum-Welch算法,屬於最大似然準則下的EM算法。目前研究者提出了多種區分性訓練方法(仍然屬於產生式模型,但使用區分性準則)進行訓練,取得了較好的效果。
