
聯想記憶可以歸結為對人腦中信息的存儲、關聯及檢索的研究,對計算機科學的各個領域都有著極其重要的指導意義。三個在聯想記憶研究領域有重大影響的代表性聯想記憶模型分別是SAM、TODAM 和Matrix。
基本介紹
- 中文名:聯想記憶模型
- 外文名:associative memory model
- 學科:控制科學與工程
- 基本釋義:對信息的存儲、關聯及檢索的研究
- 主要模型:SAM、TODAM 和Matrix
- 典型:Hopfield模型
基本概念,聯想記憶的原理及算法,原理,算法,主要模型,SAM 模型,TODAM 模型,矩陣模型,聯想記憶的優勢,
基本概念
人工神經元網路是通過模擬人的神經元網路系統信息處理的原理從而使機器具有類似的信息處理能力的一種方法,聯想記憶是人腦記憶的一種重要方式,對文章中模糊不清的字人可以通過上下文關係聯想起來,對於發生過又記不太清楚的事情,經過別人提示後仍能較清楚地回憶起。用人工神經元網路模擬人的聯想記憶也是進一步研究神經元網路的各種信息處理的基礎。
聯想記憶的研究在計算機科學和認知科學上是一個交叉的熱點問題,它可以歸結為對人腦中信息的存儲、關聯及檢索的研究,對計算機科學的各個領域都有著極其重要的指導意義。三個在聯想記憶研究領域有重大影響的代表性模型分別是SAM、TODAM 和Matrix。SAM 屬於情景記憶模型,TODAM 為語義記憶模型,Matrix模型為情景記憶與語義記憶的混合模型。
聯想記憶的原理及算法
Hopfield模型具有與人腦聯想記憶類似的能力。它能夠從缺損或模糊不清的圖象中聯想起記憶中完整、清晰的圖象來,但這種模型在進行聯想記憶時有很大局限性。以Hopfield為例,下面是聯想記憶的原理及算法。
原理
Hopfield網路是一種節點互連網路,網路的任兩節點間有一條連線,其強度稱為權,這種神經元網路是一種對稱連線,即從節點泣到節點i 的權同節點j 到i的權相等,即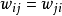 。
。
Hopfield聯想網路的權可由Hebb規則確定,網路運行時則是一個高維非線性動力學系統。當系統到達某一狀態不再運行,這個狀態稱為穩定吸引子,如果吸引子是某個樣本,則稱它為樣本吸引子,否則稱為非樣本吸引子。
對給定的一模式X ,神經元網路進行聯想過程則對應於系統以此模式為初始狀態朝某一吸引子運行的過程,若此吸引子為一樣本點,則認為此樣本是由x 聯想到的。Hopfield聯想網路有這樣兩個問題,一是網路存儲的樣本數量有限,當存儲的樣本太多時,不能保證每個樣本都是系統吸引子,即是說某些樣本根本沒有記住。Hopfield指出,對於隨機產生的樣本,網路存儲樣本的數量M<=0.15N ,N 為網路的節點數。另一局限是這樣的神經元網路對於相近的樣本不能夠區分開來,會出現這種現象,以某一樣本作初始輸入,這個樣本可能並不能聯想到自身,而是聯想到另一個與之相近的樣本。通過正交化方法可以避免這些問題,但正交化會丟失一部分信息。將一組樣本正交化也是較為困難的問題。
Hopfield網路雖有某些與人腦聯想記憶類似的特性,但與人記憶某些信息的行為還有一定差別,對一個樣本它只學習一次,而人的記憶經常是一種反覆學習過程,對於沒有記住的要重新學習,經過多次學習後則可記住所有的樣本,對於相近的樣本也能仔細地區分開來。另外,這種模型中權的對稱連線方式也不能夠反應出許多信息的實際內部結構,因為信息的分量間的關係往往是不同等的。
算法
為了解決上述問題我們提出一種與人的某些聯想記憶更相近的神經元網路模型,這種神經元網路仍是一種互連網路,但是它是非對稱的連線,即是神經元網路中兩個節點j ,i 之間的連線有兩條,權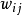 是節點i 向節點i 傳送信息的權,
是節點i 向節點i 傳送信息的權,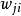 是i 接收從j發出信息的權,兩個權是不相同的。這種神經元網路的運行方式仍同Hopfield網路相似,也是一個非線性動力學系統,對於一個給定的模式對應於神經元網路的初始狀X(0),經過k步運行後狀態為X(k),則
是i 接收從j發出信息的權,兩個權是不相同的。這種神經元網路的運行方式仍同Hopfield網路相似,也是一個非線性動力學系統,對於一個給定的模式對應於神經元網路的初始狀X(0),經過k步運行後狀態為X(k),則

其中f(x)為階梯型非線性函式

網路運行到某一個吸引子為止,若這個吸引子是一個樣本點,則認為此樣本是由模式x(0)聯想起來的。
神經元網路的記憶過程對應於如下的Perceptron學習算法:
對於分量值取+1 或-1的M個二值樣本按如下方式循環排列


主要模型
三個在聯想記憶研究領域有重大影響的代表性模型分別是SAM、TODAM 和Matrix。SAM 屬於情景記憶模型,TODAM 為語義記憶模型,Matrix模型為情景記憶與語義記憶的混合模型。
SAM 模型
聯想記憶的搜尋模型SAM(Search of Associave Memory)是一個可模擬回憶和識別的情景記憶模式。在SAM 模型中,記憶內容是由“映像(image)”組成的,它們是一些相互聯繫、相對獨立的特徵集。這些映像的信息類型包括:
(1)上下文信息(即項所處的上下文);
(2)項信息(編碼在上下文中的項);
(3)項-項信息(映像與映像之間的連線)。
當要檢索記憶中的對象時,按給出的線索(cue)來進行檢索,線索類型包括:
(1)表示一個情景的上下文線索(如剛學習過的表格);
(2)項線索(如字、詞和句子);
(3)類別線索。
線索集以不同的強度激活記憶中的映像。映像以什麼樣的程度被激活取決於檢索結構(retrievaI structure),這是一個映像的線索矩陣。如圖1所示:
圖1
檢索強度取決於三個因素:編碼方式與學習的次數;學習和測試時的線索匹配程度;檢索前的預聯接。
SAM模型的建立分為兩個過程:識別和回憶。
(1)識別(Recognition)
識別是一個輸出為yes / no 式的決策過程。將所有映像的激活的整合放到一個全局匹配模型中進行匹配,若熟悉性程度F 大於某個規定值,系統回響為“舊對象”,否則回響為“新對象”。熟悉性程度F為:

其中,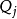 為線索,
為線索,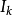 為項表中的映像,M為線索的總數,N為映像的總數,
為項表中的映像,M為線索的總數,N為映像的總數,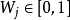 為對每個線索的注意係數,S( , )是激活 的強度。上式表明,每個映像的激活是每個線索對該映像的檢索強度的積,若一個映像對於所有的線索都有較強的檢索強度,它被激活。熟悉性程度的值則是這些激活的總和。
為對每個線索的注意係數,S( , )是激活 的強度。上式表明,每個映像的激活是每個線索對該映像的檢索強度的積,若一個映像對於所有的線索都有較強的檢索強度,它被激活。熟悉性程度的值則是這些激活的總和。
若在只是識別一個項的任務中,輸入為一個上下文線索C 和一個項線索I,設所有的注意係數為1,上式可簡化為:

(2)回憶(RecaII)
回憶的過程有以下步驟:
a.根據檢索計畫選擇刺激線索;
b.從激活集中取樣一個映像;
c.試圖恢復該映像的名稱;
d.如果該名稱被恢復,則被賦值決定是否產生回響。搜尋繼續,重複執行第(1)到(3)步,直到產生的錯誤數達到最大值。
TODAM 模型
分散式聯想記憶模型TODAM( Theory of Distributed Associative Memory)是Murdoch 提出來的。他認為一個通用的記憶理論必須回答至少四個問題:信息的表示方法;存儲和檢索的信息對象;存儲和檢索的操作特點;存儲的格式。
在TODAM 模型中,信息是以隨機變數表示,存儲和檢索的對象是項和關聯信息,存儲和檢索的操作是卷積和相關關係,信息的存儲格式是分散式的或複合型的,而不是離散的、獨立區分的。它成功地在一定程度上描述了:相似的效應;項和關聯信息的獨立性;項與關聯信息不同的權重設定;聯想的對稱性——學習了AB,可以用A來激活B,也可用B來激活A;在識別中速度- 準確率的開銷折衷等問題。
TODAM 中信息的操作有兩步:存儲和回憶。
(l)存儲(Storage)
獨立學習的信息f、g 與它們的關聯信息(f*g)的存儲是以疊加的方式得到一個複合向量,如下式表示:

其中,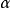 為遺忘係數,
為遺忘係數,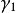 和
和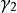 為f 和g 的權重係數,
為f 和g 的權重係數,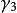 為關聯信息的權重係數( 、 、 、
為關聯信息的權重係數( 、 、 、  [0,1])。
[0,1])。
(2)回憶(RecaII)
基於線索的回憶是線索向量f與複合存儲向量M的相關關係(f # M)。
矩陣模型
由Humphreys、Bain 和Pike 研發的矩陣模型MatriX ModeI 是一個實現語義記憶和情景記憶聯想操作的混合模型。
(1)記憶內容的表示
矩陣模型的內容包括項、上下文及項與上下文的聯想:
a.項:項包括刺激、字和概念。每個項由一個特徵權重的向量表示,特徵權重指的是某特徵對一個項而言的重要程度。
b.上下文:上下文指的是項所處的背景信息,也由特徵權重的向量表示。
c.聯想:記憶內容由於內容的特徵產生聯想。聯想的類型包括:一對項之間的雙向聯想;項與上下文的雙向聯想;一對項與上下文之間的三向聯想。
(2)訪問記憶內容
在一個分散式記憶結構中,必須由給出的線索進行對記憶內容的訪問。這種檢索被稱為基於線索的檢索。線索通過兩種途徑來訪問記憶內容:匹配和檢索。
匹配:匹配即是對線索與存儲在記憶中的信息進行對比。這個過程計算線索與記憶內容的相似度,輸出結果為一個比例值。套用到該過程的任務有識別與計算熟悉性程度。
檢索:檢索即是對與線索關聯的信息的恢復,輸出的結果是一個由特徵權重向量表示的特徵信息。套用到該過程的任務有自由回憶與基於線索的回憶等。
(3)識別與基於線索的回憶
識別包括匹配的過程,即要計算線索(X和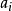 )和記憶內容M之間的相似性。該匹配過程先合併線索為一個線索聯想矩陣(x )、再計算線索矩陣(x )和記憶矩陣(M = x
)和記憶內容M之間的相似性。該匹配過程先合併線索為一個線索聯想矩陣(x )、再計算線索矩陣(x )和記憶矩陣(M = x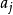 + S)之間的點積。
+ S)之間的點積。
聯想記憶的優勢
聯想記憶的研究在計算機科學和認知科學上是一個交叉的熱點問題,它可以歸結為對人腦中信息的存儲、關聯及檢索的研究,對計算機科學的各個領域都有著極其重要的指導意義。
首先,聯想記憶具有識別殘缺、畸變的輸入模式的能力,因此在模式識別、尤其是圖像識別方面套用廣泛,取得相當突出的成績。
其次,在人工智慧研究領域關於類比推理等人類思維規律的研究中,聯想記憶是推理過程中必不可少的環節:對於一個知識庫未有的新情況,它負責找出庫中已有的相似情況及其對策,從而為產生新的決策和知識奠定基礎。
再次,在突破按地址定址的傳統晶片技術的研究中,採用按內容定址方式的聯想記憶晶片是一個主流的研究方向,這項技術將會改變傳統的計算機體系結構及算法設計。
