
標籤傳播(LPA)算法是最早的基於標籤的一種算法,是所有基於標籤的算法的基礎。標籤傳播算法最大的特色是簡單、高效,缺點是每次疊代結果不穩定,準確率不高。
在標籤傳播算法基礎上改進的標籤算法有COPRA、SLPA等。
基本介紹
- 中文名:標籤傳播算法
- 外文名:LPA
算法簡介,算法基本理論,
算法簡介
標籤傳播算法(LPA)是由Zhu等人於2002年提出,它是一種基於圖的半監督學習方法,其基本思路是用已標記節點的標籤信息去預測未標記節點的標籤信息。利用樣本間的關係建立關係完全圖模型,在完全圖中,節點包括已標註和未標註數據,其邊表示兩個節點的相似度,節點的標籤按相似度傳遞給其他節點。標籤數據就像是一個源頭,可以對無標籤數據進行標註,節點的相似度越大,標籤越容易傳播。由於該算法簡單易實現,算法執行時間短,複雜度低且分類效果好,引起了國內外學者的關注,並將其廣泛地套用到多媒體信息分類、虛擬社區挖掘等領域中。本文利用關鍵字labelpropagation、標籤傳播、標籤傳遞、標記傳播、標記傳遞等詞作為關鍵字,對國內外資料庫及網路資源進行了檢索,結果發現,目前國內外相關文獻期刊論文約有90篇,其中國外82篇,國內8篇,國內外碩博論文3篇。
標籤傳播算法( LPA)算法如下:
令( x1,y1) …( xl,yl) 是已標註數據,YL={ y1…yl} ∈{ 1…C} 是類別標籤,類別數 C 已知,且均存在於標籤數據中。令( xl + 1,yl + 1) …( xl + u,yl + u) 為未標註數據,YU={ yl + 1…yl + u} 不可觀測,l << u,令數據集 X = { x1…xl + u} ∈R。問題轉換為: 從數據集 X 中,利用YL的學習,為未標註數據集YU的每個數據找到對應的標籤。
將所有數據作為節點( 包括已標註和未標註數據) ,創建一個完全連線圖,其邊的權重計算式如下:
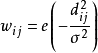
其中: dij表示任意兩個節點的歐氏距離,權重 wij受控於參數 σ。
為衡量一個節點的標註通過邊傳播到其他節點的機率,在此定義一個( l + u) × ( l + u) 機率傳遞矩陣 T 如下所示:

其中: Tij是節點 j 到 i 的傳播機率。
算法描述如下:
1. 所有節點傳播標籤一步: Y← TY;
2. 行標準化矩陣 Y 來維持類別的機率;
3. 夾逼標註數據,重複步驟 2 直到 Y 收斂。
步驟 3 可以使得節點標籤的類別分布集中在給定的類別。該算法的缺點在於需要預先標註數據,而且需要預先知識知道分類的類別個數。
算法基本理論
根據LPA算法基本理論,每個節點的標籤按相似度傳播給相鄰節點,在節點傳播的每一步,每個節點根據相鄰節點的標籤來更新自己的標籤,與該節點相似度越大,其相鄰節點對其標註的影響權值越大,相似節點的標籤越趨於一致,其標籤就越容易傳播。在標籤傳播過程中,保持已標註數據的標籤不變,使其像一個源頭把標籤傳向未標註數據。最終,當疊代過程結束時,相似節點的機率分布也趨於相似,可以劃分到同一個類別中,從而完成標籤傳播過程。
優缺點:LPA算法的優點是簡單、高效、快速;缺點是每次疊代結果不穩定,準確率不高。
在LPA算法中節點的Label有同步更新與異步更新2種更新方法。同步更新方法在二分圖中可能出現產生震盪情況。為了避免循環和保證收斂,LPA算法採用異步的策略更新節點的標籤,並在每次疊代前對節點重新進行隨機排序。
