性能度量(performance measure)是衡量模型泛化能力的評價標準,在對比不同模型的能力時,使用不同的性能度量往往會導致不同的評判結果。
基本介紹
- 中文名:性能度量
- 外文名:performance measure
最常見的性能度量,查準率、查全率與F1,F1度量,混淆矩陣,ROC與AUC,TPR與FPR,
最常見的性能度量
查準率、查全率與F1
在異常檢測的機器學習模型中,如圖1所示,1表示檢測為正常(positive),0表示檢測為異常(negative)。那么,查準率(precision)是預測為正例的樣本中預測正確的機率;查全率(recall,亦稱召回率)是正例樣本被預測正確的機率。顧名思義,對於檢測正常(檢測1)的查準率越大,檢測為正常的樣本越可信;查全率越大,檢測出來的正常樣本越多。對於檢測異常(檢測0)也是一個道理。以信息檢索為例,根據檢索結果中感興趣詞條和不感興趣詞條可以計算precision,根據檢索結果中感興趣詞條和所有感興趣詞條數目(包括未檢索出來的) 可以計算recall。 圖1
圖1
圖1F1度量
F1是基於precision與recall的調和平均(harmonic mean):
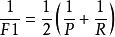
混淆矩陣
關於2分類的混淆矩陣如圖2所示。True positive(TP)中P是指預測為正例,T是指預測正確; False negative(FN)中N是指預測為反例,F是指預測錯誤。 圖2
圖2
圖2ROC與AUC
學習器對測試樣本的評估結果一般為一個實值或機率,設定一個閾值,大於閾值為正例,小於閾值為負例,因此這個實值的好壞直接決定了學習器的泛化性能,若將這些實值排序,則排序的好壞決定了學習器的性能高低。ROC曲線正是從這個角度出發來研究學習器的泛化性能,ROC曲線與P-R曲線十分類似,都是按照排序的順序逐一按照正例預測,不同的是ROC曲線以“真正例率”(True Positive Rate,簡稱TPR)為橫軸,縱軸為“假正例率”(False Positive Rate,簡稱FPR),ROC偏重研究基於測試樣本評估值的排序好壞。
TPR與FPR
下表說明P、R與TPR、FPR的對比。同時,我以判斷西瓜好壞為例(正例是預測為好瓜,反例是預測為壞瓜),簡要說明其作用。
機率指標 | 計算公式 | 說明 | 作用 |
P | 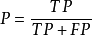 | 準確率:判斷為正例 正確的機率 | 準確率越高,檢測出來的好瓜越可靠,檢測出來的壞瓜越少 |
R | 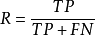 | 查全率:正例被判斷為正例的機率 | 查全率越高,檢測出來的好瓜越多,漏掉的好瓜越少 |
TPR | 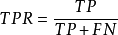 | 真正例率:正例被判斷為正例的機率 | 越高表示好瓜的樣本越難被判錯,等於查全率 |
FPR | 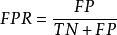 | 假正例率:反例被判斷為正例的機率 | 越高表示壞瓜的樣本越容易被判錯 |
假設,我是買家,我想要買一個好瓜。那么,我要考慮學習器的準確率,以保證買到的更可能是好瓜。
假設,我是商戶,我想把一批西瓜分成好壞兩類 方便定不同的價格。那么,我要考慮學習器的查全率,以保證好瓜都能賣高價。
假設,我是水果店HR,我想招一個員工來做 西瓜分好壞的工作。那么,我要考慮員工(學習器)的真正例率越高越好,但是挑出的好瓜越多,就會使壞瓜被誤判為好瓜的錯誤越多(假正例率越高),顧客就會不滿意。
