基本介紹
- 中文名:圖模式
- 外文名:Graphical Model
- 別稱:機率圖模型
簡介,有向和無向機率圖模型的定義,數據類型及研究課題,參見,
簡介
在機率論、統計學及機器學習中,機率圖模型(Graphical Model)是用圖論方法以表現數個獨立隨機變數之關聯的一種建模法。一個p個節點的圖中,節點i對應一個隨機變數,記為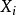 。機率圖模型被廣泛地套用於貝葉斯統計與機器學習中。
。機率圖模型被廣泛地套用於貝葉斯統計與機器學習中。
有向和無向機率圖模型的定義
在一個無向機率圖模型(Undirected Graphical Model)中,兩個節點{\displaystyle i}和{\displaystyle j}之間沒有邊相連,若且唯若它們對應的隨機變數和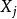 給定其它所有節點上的隨機變數條件下條件獨立。數學表述為:
給定其它所有節點上的隨機變數條件下條件獨立。數學表述為:

當所有的隨機變數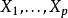 的聯合分布是多元常態分配時,
的聯合分布是多元常態分配時, 被理解為是多元常態分配的方差矩陣的逆
被理解為是多元常態分配的方差矩陣的逆 ,又稱為精度矩陣(Precision Matrix)。現代統計學中,相當大比例的關於無向圖模型的理論結果都是在多元常態分配的假設下取得的。
,又稱為精度矩陣(Precision Matrix)。現代統計學中,相當大比例的關於無向圖模型的理論結果都是在多元常態分配的假設下取得的。
在一個有向機率圖模型(Directed Graphical Model)中,兩個節點i和j之間的邊際獨立性和條件獨立性比較複雜,一般需要用貝葉斯球規則(Bayes Ball)來確定。
一類很重要的有向機率圖模型叫做有向無環機率圖模型(Directed Acyclic Graphs, 簡稱DAG),可以證明,相互關係能用DAG表示的p個隨機變數,其聯合分布函式可以被分解為根節點的邊際分布函式乘以由邊決定的那些條件機率。
數據類型及研究課題
一般機率圖模型輸入的數據是其節點上的隨機變數 的獨立重複觀測值,可記為:
的獨立重複觀測值,可記為: