
上下文無關解析就是對無關上下文的分析。
基本介紹
- 中文名:上下文無關解析
- 外文名:Context-free parsing
簡介,上下文無關的效率底線,
簡介
程式語言大部分是上下文無關語言,查詢語言通常也是上下文無關語言。英語也可以看成是上下文無關語言。這些語言中的字元串需要用編譯器、查詢引擎和各種其他應用程式分析與解釋。因此我們需要一個算法,給定上下文無關文法G,完成下列工作:
1.檢查一個字元串,確定其是否L(G)的語法形式合理成員。
2.如果是,指定其解析樹,描述其結構,從而作為進一步解釋的基礎。
程式語言真的是上下文無關語言嗎?
已經有兩種方法,可以從文法G構建一個決策過程,回答字元串W是否屬於L(G)的問題。但我們還沒有完事,還要回答下列問題:
1 第一個過程decideCFLusingGrammar要求Chomsky範式文法。第二個過程 decideCFLusingPDA要Greibach範式文法。我們希望使用自然文法,使解析過程生成自然解析樹。
2 這兩個過程都要搜尋,時間與輸入字元串長度成指數關係。但我們需要更高效的解析器,最好時間與輸入字元串長度成線性關係。
3 這兩個過程都確定L(G)中的成員關係,而不產生解析樹。
查詢語言是上下文無關語言。
1.檢查一個字元串,確定其是否L(G)的語法形式合理成員。
2.如果是,指定其解析樹,描述其結構,從而作為進一步解釋的基礎。
程式語言真的是上下文無關語言嗎?
已經有兩種方法,可以從文法G構建一個決策過程,回答字元串W是否屬於L(G)的問題。但我們還沒有完事,還要回答下列問題:
1 第一個過程decideCFLusingGrammar要求Chomsky範式文法。第二個過程 decideCFLusingPDA要Greibach範式文法。我們希望使用自然文法,使解析過程生成自然解析樹。
2 這兩個過程都要搜尋,時間與輸入字元串長度成指數關係。但我們需要更高效的解析器,最好時間與輸入字元串長度成線性關係。
3 這兩個過程都確定L(G)中的成員關係,而不產生解析樹。
查詢語言是上下文無關語言。
這些問題的算法,組織如下:
1 簡單問題:
2 實際建立解析樹:我們介紹的所有解析樹都採用語法規則進行工作。因此,要建立解析樹,只要對解析樹提供一個函式,每次採用一個規則時建立一個樹塊。
一用向前看文法減少非確定性:為了減少或消除非確定性,可以讓解析樹向前看下 一個或幾個輸入符號,然後確定進行什麼操作。
3 辭典分析:這是個預處理步驟,各個輸入符的字元串分成串大單位(令牌)的字元 串,然後輸入解析樹。
4 自頂向下解析樹:
·簡單但效率不同的遞歸向下解析樹。
·修改文法進行自頂向下解析。
. LL解析。
5 自底而上解析樹:
.簡單而效率不高的Cocke—Kasami—Younger(CKY)算法。
·LL解析。
6 英文和其他自然語言解析。
1 簡單問題:
2 實際建立解析樹:我們介紹的所有解析樹都採用語法規則進行工作。因此,要建立解析樹,只要對解析樹提供一個函式,每次採用一個規則時建立一個樹塊。
一用向前看文法減少非確定性:為了減少或消除非確定性,可以讓解析樹向前看下 一個或幾個輸入符號,然後確定進行什麼操作。
3 辭典分析:這是個預處理步驟,各個輸入符的字元串分成串大單位(令牌)的字元 串,然後輸入解析樹。
4 自頂向下解析樹:
·簡單但效率不同的遞歸向下解析樹。
·修改文法進行自頂向下解析。
. LL解析。
5 自底而上解析樹:
.簡單而效率不高的Cocke—Kasami—Younger(CKY)算法。
·LL解析。
6 英文和其他自然語言解析。
上下文無關的效率底線
上下文無關解析的效率底線如下。設n為要解析的字元串長度,則:
1 存在簡單的算法(CKY),可以在 時間內解析任何上下文無關語言。儘管這比模擬所建立的非確定性PDA所要的指數級時間好,但對許多實際套用仍然不夠好。此外,CKY要求文法為Chomsky範式。CKY還有一個更複雜的版本:可以在接近
時間內解析任何上下文無關語言。儘管這比模擬所建立的非確定性PDA所要的指數級時間好,但對許多實際套用仍然不夠好。此外,CKY要求文法為Chomsky範式。CKY還有一個更複雜的版本:可以在接近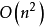 時間內解析任何上下文無關語言。
時間內解析任何上下文無關語言。
2 存在一個算法,可以使解析大部分上下文無關語言(包括許多我們關心的上下文無關語言,如大多數程式語言和查詢語言)的時間減到Dm)。可以手工建立比較直觀的自頂向下算法。還有更高效更複雜的由下而上算法,但利用一些工具可以方便地建立實用的自下而上解析器。
1 存在簡單的算法(CKY),可以在
2 存在一個算法,可以使解析大部分上下文無關語言(包括許多我們關心的上下文無關語言,如大多數程式語言和查詢語言)的時間減到Dm)。可以手工建立比較直觀的自頂向下算法。還有更高效更複雜的由下而上算法,但利用一些工具可以方便地建立實用的自下而上解析器。
3 英文和其他自然語言比解析大多數人工語言難,因為人工語言的設計可以考慮到解析效率。
