
f-measure是一種統計量,F-Measure又稱為F-Score,F-Measure是Precision和Recall加權調和平均,是IR(信息檢索)領域的常用的一個評價標準,常用於評價分類模型的好壞。
在f-measure函式中,當參數α=1時,F1綜合了P和R的結果,當F1較高時則能說明試驗方法比較有效。
基本介紹
- 外文名:f-measure
- 含義:是一種統計量
- 別稱:F-Score
F1-Measure,準確率/精確率/召回率,概念介紹,精確率與召回率的關係,
F1-Measure
計算公式為:
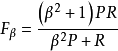
其中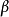 是參數,P是精確率(Precision),R是召回率(Recall)。
是參數,P是精確率(Precision),R是召回率(Recall)。
當參數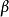 =1時,就是最常見的F1-Measure了:
=1時,就是最常見的F1-Measure了:
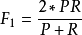
準確率/精確率/召回率
準確率(accuracy),精確率(Precision)和召回率(Recall)是信息檢索,人工智慧,和搜尋引擎的設計中很重要的幾個概念和指標。中文中這幾個評價指標翻譯各有不同,所以一般情況下推薦使用英文。
概念介紹
先假定一個具體場景作為例子。
假如某個班級有男生80人,女生20人,總計100人.目標是找出所有女生.
某人挑選出50個人,其中20人是女生,另外還錯誤的把30個男生也當作女生挑選出來了.
作為評估者的你需要來評估(evaluation)下他的工作
某人挑選出50個人,其中20人是女生,另外還錯誤的把30個男生也當作女生挑選出來了.
作為評估者的你需要來評估(evaluation)下他的工作
首先我們可以計算準確率(accuracy),其定義是: 對於給定的測試數據集,分類器正確分類的樣本數與總樣本數之比。也就是損失函式是0-1損失時測試數據集上的準確率.
這樣說聽起來有點抽象,簡單說就是,前面的場景中,實際情況是那個班級有男的和女的兩類,某人(也就是定義中所說的分類器)他又把班級中的人分為男女兩類。accuracy需要得到的是此君分正確的人占總人數的比例。很容易,我們可以得到:他把其中70(20女+50男)人判定正確了,而總人數是100人,所以它的accuracy就是70 %(70 / 100).
由準確率,我們的確可以在一些場合,從某種意義上得到一個分類器是否有效,但它並不總是能有效的評價一個分類器的工作。舉個例子,google抓取了argcv 100個頁面,而它索引中共有10,000,000個頁面,隨機抽一個頁面,分類下,這是不是argcv的頁面呢?如果以accuracy來判斷我的工作,那我會把所有的頁面都判斷為"不是argcv的頁面",因為我這樣效率非常高(return false,一句話),而accuracy已經到了99.999%(9,999,900/10,000,000),完爆其它很多分類器辛辛苦苦算的值,而我這個算法顯然不是需求期待的,那怎么解決呢?這就是precision,recall和f1-measure出場的時間了.
在說precision,recall和f1-measure之前,我們需要先需要定義TP,FN,FP,TN四種分類情況.
按照前面例子,我們需要從一個班級中的人中尋找所有女生,如果把這個任務當成一個分類器的話,那么女生就是我們需要的,而男生不是,所以我們稱女生為"正類",而男生為"負類".
相關(Relevant),正類 | 無關(NonRelevant),負類 | |
被檢索到(Retrieved) | true positives(TP 正類判定為正類,例子中就是正確的判定"這位是女生") | false positives(FP 負類判定為正類,"存偽",例子中就是分明是男生卻判斷為女生) |
未被檢索到(Not Retrieved) | false negatives(FN 正類判定為負類,"去真",例子中就是,分明是女生,這哥們卻判斷為男生--梁山伯同學犯的錯就是這個) | true negatives(TN 負類判定為負類,也就是一個男生被判斷為男生) |
通過這張表,我們可以很容易得到例子中這幾個分類的值:TP=20,FP=30,FN=0,TN=50.
精確率(precision)的公式是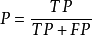 ,它計算的是所有被檢索到的item(TP+FP)中,"應該被檢索到的item(TP)”占的比例。
,它計算的是所有被檢索到的item(TP+FP)中,"應該被檢索到的item(TP)”占的比例。
在例子中就是希望知道此君得到的所有人中,正確的人(也就是女生)占有的比例.所以其precision也就是40%(20女生/(20女生+30誤判為女生的男生)).
召回率(recall)的公式是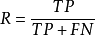 ,它計算的是所有檢索到的item(TP)占所有"應該被檢索到的item(TP+FN)"的比例。
,它計算的是所有檢索到的item(TP)占所有"應該被檢索到的item(TP+FN)"的比例。
在例子中就是希望知道此君得到的女生占本班中所有女生的比例,所以其recall也就是100%(20女生/(20女生+ 0 誤判為男生的女生))
前文中提到F1-measure的計算公式是 其推導其實也很簡單。
定義:
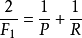
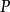
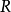
可得:
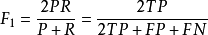
精確率與召回率的關係
“精確率”與“召回率”雖然沒有必然的關係(從上面公式中可以看到),然而在大規模數據集合中,這兩個指標卻是相互制約的。
由於“檢索策略”並不完美,希望更多相關的文檔被檢索到時,放寬“檢索策略”時,往往也會伴隨出現一些不相關的結果,從而使準確率受到影響。
而希望去除檢索結果中的不相關文檔時,務必要將“檢索策略”定的更加嚴格,這樣也會使有一些相關的文檔不再能被檢索到,從而使召回率受到影響。
凡是涉及到大規模數據集合的檢索和選取,都涉及到“召回率”和“精確率”這兩個指標。而由於兩個指標相互制約,我們通常也會根據需要為“檢索策略”選擇一個合適的度,不能太嚴格也不能太松,尋求在召回率和精確率中間的一個平衡點。這個平衡點由具體需求決定。
