
基本介紹
- 中文名:編碼原理
- 外文名:Encoding Theory
- 學科:計算機科學、通信
- 定義:編碼的屬性及套用的研究
- 目的:除冗餘、錯誤檢查
- 方法:低速、高速、線性、非線性
簡介,編碼方法,
簡介
編碼原理是對編碼的屬性及其各自適用於具體套用的方法研究。編碼用於數據壓縮,加密,糾錯和網路。編碼在各種科學學科(如信息理論,電氣工程,數學,語言學和計算機科學)都有研究 -旨在設計高效可靠的數據傳輸方法。這通常涉及去除冗餘以及傳送數據中的錯誤的校正或檢測。實現編碼的具體方法和電路很多,方法有低速編碼和高速編碼、線性編碼和非線性編碼;電路有逐次比較型、級聯型和混合型編碼。編碼原理按照套用來分可以分為算術編碼原理,音頻編碼原理、圖像編碼原理、字元編碼原理等。
編碼方法
這裡主要介紹線性編碼有關內容
線性編碼
術語代數編碼理論表示編碼原理的子領域,其編碼性質以代數術語表示,然後進一步研究。
代數編碼理論基本上分為兩大類代碼:
線性分組碼
卷積碼
它分析一個編碼的以下三個特性-主要是:
碼字長度
有效代碼字總數
兩個有效代碼字之間的最小距離,主要使用漢明距離,有時也使用其他距離像Lee距離。
線性分組碼
線性分組碼具有的特性的線性度,即,任何兩個碼字的總和也是一個編碼字,並且它們被套用到組的源比特中,因此稱為線性分組碼。有分組碼不是線性的,但是很難證明編碼是沒有這個屬性的編碼。
線性分組碼由其符號字母(例如,二進制或三元)和參數(n,m,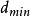 )組成,其中
)組成,其中
n是碼字的長度,以符號表示,
m是將一次用於編碼的源符號的數量,
有許多類型的線性分組碼,如循環碼(如漢明碼)、重複代碼、奇偶校驗碼、多項式編碼(例如BCH碼)、里德 - 所羅門編碼、代數幾何編碼、里德 - 穆勒編碼、完美編碼。
編碼原理使用N維球體模型。例如,可以在桌面上或三維中將多少便士包裝成圓圈,可以將多少個彈珠包裝在一個球面上。其他注意事項輸入編碼的選擇。例如,六邊形包裝成矩形框的約束將在角落留下空的空間。隨著尺寸越來越大,空白空間的百分比越來越小。但是在某些維度上,包裝使用所有空間,這些代碼是所謂的“完美”代碼。唯一非常重要和有用的完美編碼是距離為3漢明碼,其參數滿足(2 r - 1,2 r - 1 - r,3)和[23,12,7]二進制和[11,6,5 ]三重Golay碼。
另一個編碼屬性是單個碼字可能具有的鄰居的數量。再次,以便士為例。首先我們把便士打包成矩形格線。每一分錢將有4個鄰近的鄰居(在距離更遠的角落有4個)。在六邊形,每一分錢將有6個近鄰。當我們增加尺寸時,近鄰的數量增加非常快。結果是使接收端選擇鄰居(因此錯誤)的噪聲的方式也增加。這是分組碼以及所有編碼的基本限制。可能更難對單個鄰居造成錯誤,但鄰居數量可能足夠大,因此總錯誤機率實際上會受到影響。
線性分組碼的屬性可以套用於很多套用。例如,線性分組碼的校正子集合唯一性被用格線成形,是最有名的形狀碼之一。感測器網路中使用相同的屬性進行分散式原始碼編碼。
卷積碼
如果特定的一致監督關係不是在一個碼字中實現,而是在個碼字中實現,這種碼稱為卷積碼。卷積碼可用移位暫存器來實現,這種卷積編碼器的輸出可看作是輸入信息碼元序列與編碼器回響函式的卷積。能糾正突發錯誤的哈格伯爾格碼也是一種卷積碼。在平穩高斯噪聲干擾的信道上採用序貫解碼方法的卷積碼有很好的性能,能用於衛星通信和深空通信。
UTF-8 編碼原理
為了統一全世界各國語言文字和專業領域符號(例如數學符號、樂譜符號)的編碼,ISO制定了ISO 10646標準,也稱為UCS(Universal Character Set)。UCS編碼的長度是31位,可以表示231個字元。如果兩個字元編碼的高位相同,只有低16位不同,則它們屬於一個平面(Plane),所以一個平面由216個字元組成。目前常用的大部分字元都位於第一個平面(編碼範圍是U-00000000~U-0000FFFD),稱為BMP(Basic Multilingual Plane)或Plane 0,為了向後兼容,其中編號為0~256的字元和Latin-1相同。UCS編碼通常用U-xxxxxxxx這種形式表示,而BMP的編碼通常用 U+xxxx這種形式表示,其中x是十六進制數字。在ISO制定UCS的同時,另一個由廠商聯合組織也在著手制定這樣的編碼,稱為Unicode,後來兩家聯手制定統一的編碼,但各自發布各自的標準文檔,所以UCS編碼和Unicode碼是相同的。
有了字元編碼,另一個問題就是這樣的編碼在計算機中怎么表示。現在已經不可能用一個位元組表示一個字元了,最直接的想法就是用四個位元組表示一個字元,這種表示方法稱為UCS-4或UTF- 32,UTF是Unicode Transformation Format的縮寫。一方面這樣比較浪費存儲空間,由於常用字元都集中在BMP,高位的兩個位元組通常是0,如果只用ASCII碼或Latin-1,高位的三個位元組都是0。另一種比較節省存儲空間的辦法是用兩個位元組表示一個字元,稱為UCS-2或UTF-16,這樣只能表示BMP中的字元,但BMP中有一些擴展字元,可以用兩個這樣的擴展字元表示其它平面的字元,稱為Surrogate Pair。無論是UTF-32還是UTF-16都有一個更嚴重的問題是和C語言不兼容,在C語言中0位元組表示字元串結尾,庫函式strlen、 strcpy等等都依賴於這一點,如果字元串用UTF-32存儲,其中有很多0位元組並不表示字元串結尾,這就亂套了。
UNIX之父Ken Thompson提出的UTF-8編碼很好地解決了這些問題,現在得到廣泛套用。UTF-8具有以下性質:
* 編碼為U+0000~U+007F的字元只占一個位元組,就是0x00~0x7F,和ASCII碼兼容。
* 編碼大於U+007F的字元用2~6個位元組表示,每個位元組的最高位都是1,而ASCII碼的最高位都是0,因此非ASCII碼字元的表示中不會出現ASCII碼位元組(也就不會出現0位元組)。
* 用於表示非ASCII碼字元的多位元組序列中,第一個位元組的取值範圍是0xC0~0xFD,根據它可以判斷後面有多少個位元組也屬於當前字元的編碼。後面每個位元組的取值範圍都是0x80~0xBF,見下面的詳細說明。
* UCS定義的所有231個字元都可以用UTF-8編碼表示出來。
* UTF-8編碼最長6個位元組,BMP字元的UTF-8編碼最長三個位元組。
* 0xFE和0xFF這兩個位元組在UTF-8編碼中不會出現。
具體來說,UTF-8編碼有以下幾種格式:
U-00000000 – U-0000007F: 0xxxxxxx
U-00000080 – U-000007FF: 110xxxxx 10xxxxxx
U-00000800 – U-0000FFFF: 1110xxxx 10xxxxxx10xxxxxx
U-00010000 – U-001FFFFF: 11110xxx 10xxxxxx10xxxxxx 10xxxxxx
U-00200000 – U-03FFFFFF: 111110xx 10xxxxxx10xxxxxx 10xxxxxx 10xxxxxx
U-04000000 – U-7FFFFFFF: 1111110x 10xxxxxx10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
第一個位元組要么最高位是0(ASCII位元組),要么最高兩位都是1,最高位之後1的個數決定後面有多少個位元組也屬於當前字元編碼,例如111110xx,最高位之後還有四個1,表示後面有四個位元組也屬於當前字元的編碼。後面每個位元組的最高兩位都是10,可以和第一個位元組區分開。這樣的設計有利於誤碼同步,例如在網路傳輸過程中丟失了幾個位元組,很容易判斷當前字元是不完整的,也很容易找到下一個字元從哪裡開始,結果頂多丟掉一兩個字元,而不會導致後面的編碼解釋全部混亂了。上面的格式中標為x的位就是UCS編碼,最後一種6位元組的格式中x位有31個,可以表示31位的UCS編碼,UTF-8就像一列火車,第一個位元組是車頭,後面每個位元組是車廂,其中承載的貨物是UCS編碼。UTF-8規定承載的UCS編碼以大端表示,也就是說第一個位元組中的x是UCS編碼的高位,後面位元組中的x是UCS編碼的低位。
例如U+00A9(©字元)的二進制是10101001,編碼成UTF-8是11000010 10101001(0xC2 0xA9),但不能編碼成11100000 10000010 10101001,UTF-8規定每個字元只能用儘可能少的位元組來編碼。
