
稀疏自編碼器是一種無監督機器學習算法,通過計算自編碼的輸出與原輸入的誤差,不斷調節自編碼器的參數,最終訓練出模型。自編碼器可以用於壓縮輸入信息,提取有用的輸入特徵。
基本介紹
- 中文名:稀疏自編碼器
- 外文名:Sparse Autoencoder
- 領域:深度學習
提出思路,算法原理,與自動編碼器的區別,為什麼要用稀疏自編碼器,稀疏自編碼器的解釋,通過tensorflow實現的稀疏自編碼器,初始化參數,初始化訓練集數據,通過xvaier初始化第一層的權重值,計算代價函式,可視化自編碼器,主函式,
提出思路
自編碼器最初提出是基於降維的思想,但是當隱層節點比輸入節點多時,自編碼器就會失去自動學習樣本特徵的能力,此時就需要對隱層節點進行一定的約束,與降噪自編碼器的出發點一樣,高維而稀疏的表達是好的,因此提出對隱層節點進行一些稀疏性的限值。稀疏自編碼器就是在傳統自編碼器的基礎上通過增加一些稀疏性約束得到的。這個稀疏性是針對自編碼器的隱層神經元而言的,通過對隱層神經元的大部分輸出進行抑制使網路達到一個稀疏的效果。
算法原理
假設我們只有一個沒有帶類別標籤的訓練樣本集合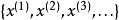 ,其中
,其中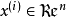 。自編碼神經網路是一種無監督學習算法,它使用了反向傳播算法,並讓目標值等於輸入值,比如
。自編碼神經網路是一種無監督學習算法,它使用了反向傳播算法,並讓目標值等於輸入值,比如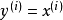 。下圖是一個自編碼神經網路(圖一)的示例。
。下圖是一個自編碼神經網路(圖一)的示例。 圖一
圖一
圖一自編碼神經網路嘗試學習一個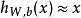 的函式。換句話說,它嘗試逼近一個恆等函式,從而使得輸出
的函式。換句話說,它嘗試逼近一個恆等函式,從而使得輸出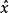 接近於輸入
接近於輸入 。恆等函式雖然看上去不太有學習的意義,但是當我們為自編碼神經網路加入某些限制,比如限定隱藏神經元的數量,我們就可以從輸入數據中發現一些有趣的結構。舉例來說,假設某個自編碼神經網路的輸入
。恆等函式雖然看上去不太有學習的意義,但是當我們為自編碼神經網路加入某些限制,比如限定隱藏神經元的數量,我們就可以從輸入數據中發現一些有趣的結構。舉例來說,假設某個自編碼神經網路的輸入 是一張
是一張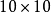 圖像(共100個像素)的像素灰度值,於是
圖像(共100個像素)的像素灰度值,於是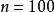 ,其隱藏層
,其隱藏層 中有50個隱藏神經元。注意,輸出也是100維的
中有50個隱藏神經元。注意,輸出也是100維的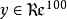 。由於只有50個隱藏神經元,我們迫使自編碼神經網路去學習輸入數據的'''壓縮'''表示,也就是說,它必須從50維的隱藏神經元激活度向量
。由於只有50個隱藏神經元,我們迫使自編碼神經網路去學習輸入數據的'''壓縮'''表示,也就是說,它必須從50維的隱藏神經元激活度向量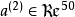 中'''重構'''出100維的像素灰度值輸入
中'''重構'''出100維的像素灰度值輸入 。如果網路的輸入數據是完全隨機的,比如每一個輸入
。如果網路的輸入數據是完全隨機的,比如每一個輸入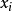 都是一個跟其它特徵完全無關的獨立同分布高斯隨機變數,那么這一壓縮表示將會非常難學習。但是如果輸入數據中隱含著一些特定的結構,比如某些輸入特徵是彼此相關的,那么這一算法就可以發現輸入數據中的這些相關性。事實上,這一簡單的自編碼神經網路通常可以學習出一個跟主元分析(PCA)結果非常相似的輸入數據的低維表示。
都是一個跟其它特徵完全無關的獨立同分布高斯隨機變數,那么這一壓縮表示將會非常難學習。但是如果輸入數據中隱含著一些特定的結構,比如某些輸入特徵是彼此相關的,那么這一算法就可以發現輸入數據中的這些相關性。事實上,這一簡單的自編碼神經網路通常可以學習出一個跟主元分析(PCA)結果非常相似的輸入數據的低維表示。
我們剛才的論述是基於隱藏神經元數量較小的假設。但是即使隱藏神經元的數量較大(可能比輸入像素的個數還要多),我們仍然通過給自編碼神經網路施加一些其他的限制條件來發現輸入數據中的結構。具體來說,如果我們給隱藏神經元加入稀疏性限制,那么自編碼神經網路即使在隱藏神經元數量較多的情況下仍然可以發現輸入數據中一些有趣的結構。
稀疏性可以被簡單地解釋如下。如果當神經元的輸出接近於1的時候我們認為它被激活,而輸出接近於0的時候認為它被抑制,那么使得神經元大部分的時間都是被抑制的限制則被稱作稀疏性限制。這裡我們假設的神經元的激活函式是sigmoid函式。如果你使用tanh作為激活函式的話,當神經元輸出為-1的時候,我們認為神經元是被抑制的。
注意到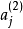 表示隱藏神經元
表示隱藏神經元 的激活度,但是這一表示方法中並未明確指出哪一個輸入
的激活度,但是這一表示方法中並未明確指出哪一個輸入 帶來了這一激活度。所以我們將使用
帶來了這一激活度。所以我們將使用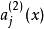 來表示在給定輸入為
來表示在給定輸入為 情況下,自編碼神經網路隱藏神經元
情況下,自編碼神經網路隱藏神經元 的激活度。
的激活度。
進一步,讓
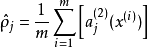
表示隱藏神經元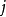 的平均活躍度(在訓練集上取平均)。我們可以近似的加入一條限制
的平均活躍度(在訓練集上取平均)。我們可以近似的加入一條限制
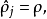
其中,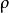 是'''稀疏性參數''',通常是一個接近於0的較小的值(比如
是'''稀疏性參數''',通常是一個接近於0的較小的值(比如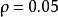 )。換句話說,我們想要讓隱藏神經元
)。換句話說,我們想要讓隱藏神經元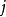 的平均活躍度接近0.05。為了滿足這一條件,隱藏神經元的活躍度必須接近於0。
的平均活躍度接近0.05。為了滿足這一條件,隱藏神經元的活躍度必須接近於0。
為了實現這一限制,我們將會在我們的最佳化目標函式中加入一個額外的懲罰因子,而這一懲罰因子將懲罰那些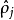 和
和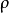 有顯著不同的情況從而使得隱藏神經元的平均活躍度保持在較小範圍內。懲罰因子的具體形式有很多種合理的選擇,我們將會選擇以下這一種:
有顯著不同的情況從而使得隱藏神經元的平均活躍度保持在較小範圍內。懲罰因子的具體形式有很多種合理的選擇,我們將會選擇以下這一種:
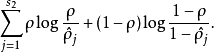
這裡,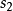 是隱藏層中隱藏神經元的數量,而索引
是隱藏層中隱藏神經元的數量,而索引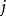 依次代表隱藏層中的每一個神經元。如果你對相對熵(KL divergence)比較熟悉,這一懲罰因子實際上是基於它的。於是懲罰因子也可以被表示為
依次代表隱藏層中的每一個神經元。如果你對相對熵(KL divergence)比較熟悉,這一懲罰因子實際上是基於它的。於是懲罰因子也可以被表示為
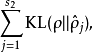
其中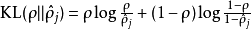 是一個以
是一個以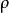 為均值和一個以
為均值和一個以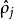 為均值的兩個伯努利隨機變數之間的相對熵。相對熵是一種標準的用來測量兩個分布之間差異的方法。(如果你沒有見過相對熵,不用擔心,所有你需要知道的內容都會被包含在這份筆記之中。)
為均值的兩個伯努利隨機變數之間的相對熵。相對熵是一種標準的用來測量兩個分布之間差異的方法。(如果你沒有見過相對熵,不用擔心,所有你需要知道的內容都會被包含在這份筆記之中。)
這一懲罰因子有如下性質,當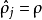 時
時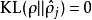 ,並且隨著
,並且隨著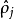 與
與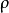 之間的差異增大而單調遞增。舉例來說,在下圖中,我們設定
之間的差異增大而單調遞增。舉例來說,在下圖中,我們設定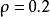 並且畫出了相對熵值
並且畫出了相對熵值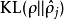 隨著
隨著 變化的變化(圖二)。
變化的變化(圖二)。 圖二
圖二
圖二我們可以看出,相對熵在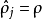 時達到它的最小值0,而當
時達到它的最小值0,而當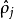 靠近0或者1的時候,相對熵則變得非常大(其實是趨向於
靠近0或者1的時候,相對熵則變得非常大(其實是趨向於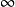 )。所以,最小化這一懲罰因子具有使得
)。所以,最小化這一懲罰因子具有使得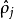 靠近
靠近 的效果。
的效果。
我們的總體代價函式可以表示為
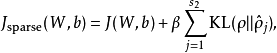
其中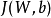 如之前所定義,而
如之前所定義,而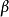 控制稀疏性懲罰因子的權重。
控制稀疏性懲罰因子的權重。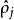 項則也(間接地)取決於
項則也(間接地)取決於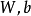 ,因為它是隱藏神經元
,因為它是隱藏神經元 的平均激活度,而隱藏層神經元的激活度取決於
的平均激活度,而隱藏層神經元的激活度取決於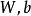 。
。
為了對相對熵進行導數計算,我們可以使用一個易於實現的技巧,這只需要在你的程式中稍作改動即可。具體來說,前面在後向傳播算法中計算第二層(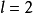 )更新的時候我們已經計算了
)更新的時候我們已經計算了
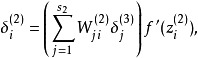
我們將其換成
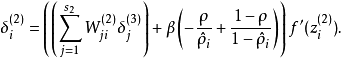
就可以了。
有一個需要注意的地方就是我們需要知道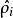 來計算這一項更新。所以在計算任何神經元的後向傳播之前,你需要對所有的訓練樣本計算一遍前向傳播,從而獲取平均激活度。如果你的訓練樣本可以小到被整個存到記憶體之中(對於編程作業來說,通常如此),你可以方便地在你所有的樣本上計算前向傳播並將得到的激活度存入記憶體並且計算平均激活度 。然後你就可以使用事先計算好的激活度來對所有的訓練樣本進行後向傳播的計算。如果你的數據量太大,無法全部存入記憶體,你就可以掃過你的訓練樣本並計算一次前向傳播,然後將獲得的結果累積起來並計算平均激活度
來計算這一項更新。所以在計算任何神經元的後向傳播之前,你需要對所有的訓練樣本計算一遍前向傳播,從而獲取平均激活度。如果你的訓練樣本可以小到被整個存到記憶體之中(對於編程作業來說,通常如此),你可以方便地在你所有的樣本上計算前向傳播並將得到的激活度存入記憶體並且計算平均激活度 。然後你就可以使用事先計算好的激活度來對所有的訓練樣本進行後向傳播的計算。如果你的數據量太大,無法全部存入記憶體,你就可以掃過你的訓練樣本並計算一次前向傳播,然後將獲得的結果累積起來並計算平均激活度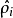 (當某一個前向傳播的結果中的激活度
(當某一個前向傳播的結果中的激活度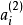 被用於計算平均激活度
被用於計算平均激活度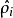 之後就可以將此結果刪除)。然後當你完成平均激活度
之後就可以將此結果刪除)。然後當你完成平均激活度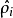 的計算之後,你需要重新對每一個訓練樣本做一次前向傳播從而可以對其進行後向傳播的計算。對於後一種情況,你對每一個訓練樣本需要計算兩次前向傳播,所以在計算上的效率會稍低一些。
的計算之後,你需要重新對每一個訓練樣本做一次前向傳播從而可以對其進行後向傳播的計算。對於後一種情況,你對每一個訓練樣本需要計算兩次前向傳播,所以在計算上的效率會稍低一些。
證明上面算法能達到梯度下降效果的完整推導過程不再本教程的範圍之內。不過如果你想要使用經過以上修改的後向傳播來實現自編碼神經網路,那么你就會對目標函式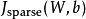 做梯度下降。使用梯度驗證方法,你可以自己來驗證梯度下降算法是否正確。
做梯度下降。使用梯度驗證方法,你可以自己來驗證梯度下降算法是否正確。
與自動編碼器的區別
在自動編碼器AutoEncoder的基礎上加上L1的正則限制(L1主要是約束每一層中的節點中大部分都要為0,只有少數不為0,這就是Sparse名字的來源),我們就可以得到Sparse AutoEncoder法。
如圖三,其實就是限制每次得到的表達code儘量稀疏。因為稀疏的表達往往比其他的表達要有效(人腦好像也是這樣的,某個輸入只是刺激某些神經元,其他的大部分的神經元是受到抑制的) 圖三
圖三
圖三為什麼要用稀疏自編碼器
對於沒有帶類別標籤的數據,由於為其增加類別標記是一個非常麻煩的過程,因此我們希望機器能夠自己學習到樣本中的一些重要特徵。通過對隱藏層施加一些限制,能夠使得它在惡劣的環境下學習到能最好表達樣本的特徵,並能有效地對樣本進行降維。這種限制可以是對隱藏層稀疏性的限制。
如果給定一個神經網路,我們假設其輸出與輸入是相同的,然後訓練調整其參數,得到每一層中的權重。自然地,我們就得到了輸入的幾種不同表示(每一層代表一種表示),這些表示就是特徵。自動編碼器就是一種儘可能復現輸入信號的神經網路。為了實現這種復現,自動編碼器就必須捕捉可以代表輸入數據的最重要的因素,就像PCA那樣,找到可以代表原信息的主要成分。
當然,我們還可以繼續加上一些約束條件得到新的Deep Learning方法,如:如果在AutoEncoder的基礎上加上L1的Regularity限制(L1主要是約束隱含層中的節點中大部分都要為0,只有少數不為0,這就是Sparse名字的來源),我們就可以得到Sparse AutoEncoder法。
之所以要將隱含層稀疏化,是由於,如果隱藏神經元的數量較大(可能比輸入像素的個數還要多),不稀疏化我們無法得到輸入的壓縮表示。具體來說,如果我們給隱藏神經元加入稀疏性限制,那么自編碼神經網路即使在隱藏神經元數量較多的情況下仍然可以發現輸入數據中一些有趣的結構。
如果給定一個神經網路,我們假設其輸出與輸入是相同的,然後訓練調整其參數,得到每一層中的權重。自然地,我們就得到了輸入的幾種不同表示(每一層代表一種表示),這些表示就是特徵。自動編碼器就是一種儘可能復現輸入信號的神經網路。為了實現這種復現,自動編碼器就必須捕捉可以代表輸入數據的最重要的因素,就像PCA那樣,找到可以代表原信息的主要成分。
當然,我們還可以繼續加上一些約束條件得到新的Deep Learning方法,如:如果在AutoEncoder的基礎上加上L1的Regularity限制(L1主要是約束隱含層中的節點中大部分都要為0,只有少數不為0,這就是Sparse名字的來源),我們就可以得到Sparse AutoEncoder法。
之所以要將隱含層稀疏化,是由於,如果隱藏神經元的數量較大(可能比輸入像素的個數還要多),不稀疏化我們無法得到輸入的壓縮表示。具體來說,如果我們給隱藏神經元加入稀疏性限制,那么自編碼神經網路即使在隱藏神經元數量較多的情況下仍然可以發現輸入數據中一些有趣的結構。
稀疏自編碼器的解釋
稀疏性可以被簡單地解釋如下。如果當神經元的輸出接近於1的時候我們認為它被激活,而輸出接近於0的時候認為它被抑制,那么使得神經元大部分的時間都是被抑制的限制則被稱作稀疏性限制。這裡我們假設的神經元的激活函式是sigmoid函式。如果你使用tanh作為激活函式的話,當神經元輸出為-1的時候,我們認為神經元是被抑制的。
通過tensorflow實現的稀疏自編碼器
初始化參數
input_nodes = 8*8 //輸入節點數hidden_size = 100//隱藏節點數output_nodes = 8*8//輸出節點數
初始化訓練集數據
從mat檔案中讀取圖像塊,隨機生成10000個8*8的圖像塊。
def sampleImage(): mat = scipy.io.loadmat('F:/ml/code/IMAGES.mat') pic = mat['IMAGES'] shape = pic.shape patchsize = 8 numpatches = 1000 patches = [] i = np.random.randint(0, shape[0]-patchsize,numpatches) j = np.random.randint(0, shape[1]-patchsize, numpatches) k = np.random.randint(0, shape[2], numpatches) for l in range(numpatches): temp = pic[i[l]:(i[l]+patchsize), j[l]:(j[l]+patchsize), k[l]] temp = temp.reshape(patchsize*patchsize) patches.append(temp) return patches通過xvaier初始化第一層的權重值
def xvaier_init(input_size, output_size): low = -np.sqrt(6.0/(input_nodes+output_nodes)) high = -low return tf.random_uniform((input_size, output_size), low, high, dtype = tf.float32)
計算代價函式
代價函式由三部分組成,均方差項,權重衰減項,以及稀疏因子項。
def computecost(w,b,x,w1,b1): p = 0.1 beta = 3 lamda = 0.00001 hidden_output = tf.sigmoid(tf.matmul(x,w) + b) pj = tf.reduce_mean(hidden_output, 0) sparse_cost = tf.reduce_sum(p*tf.log(p/pj)+(1-p)*tf.log((1-p)/(1-pj))) output = tf.sigmoid(tf.matmul(hidden_output,w1)+b1) regular = lamda*(tf.reduce_sum(w*w)+tf.reduce_sum(w1*w1))/2 cross_entropy = tf.reduce_mean(tf.pow(output - x, 2))/2 +sparse_cost*beta + regular #+ regular+sparse_cost*beta return cross_entropy, hidden_output, output
可視化自編碼器
為了使隱藏單元得到最大激勵(隱藏單元需要什麼樣的特徵輸入),將這些特徵輸入顯示出來。
def show_image(w): sum = np.sqrt(np.sum(w**2, 0)) changedw = w/sum a,b = changedw.shape c = np.sqrt(a*b) d = int(np.sqrt(a)) e = int(c/d) buf = 1 newimage = -np.ones((buf+(d+buf)*e,buf+(d+buf)*e)) k = 0 for i in range(e): for j in range(e): maxvalue = np.amax(changedw[:,k]) if(maxvalue<0): maxvalue = -maxvalue newimage[(buf+i*(d+buf)):(buf+i*(d+buf)+d),(buf+j*(d+buf)):(buf+j*(d+buf)+d)] = np.reshape(changedw[:,k],(d,d))/maxvalue k+=1 plt.figure("beauty") plt.imshow(newimage) plt.axis('off') plt.show() 主函式
通過AdamOptimizer下降誤差,調節參數。
def main(): w = tf.Variable(xvaier_init(input_nodes, hidden_size)) b = tf.Variable(tf.truncated_normal([hidden_size],0.1)) x = tf.placeholder(tf.float32, shape = [None, input_nodes]) w1 = tf.Variable(tf.truncated_normal([hidden_size,input_nodes], -0.1, 0.1)) b1 = tf.Variable(tf.truncated_normal([output_nodes],0.1)) cost, hidden_output, output = computecost(w,b,x,w1,b1) train_step = tf.train.AdamOptimizer().minimize(cost) train_x = sampleImage() sess = tf.Session() sess.run(tf.global_variables_initializer()) for i in range(100000): _,hidden_output_, output_,cost_,w_= sess.run([train_step, hidden_output, output,cost,w], feed_dict = {x : train_x}) if i%1000 == 0: print(hidden_output_) print(output_) print(cost_) np.save("weights1.npy", w_) show_image(w_)