(2)S:表示系統的吞吐率,也稱為識別效率,即所有標籤成功傳送的、有效的總的數據包量,也就是在時間 T 內標籤與閱讀器成功通信的平均次數,因此吞吐率S 等於 G 與成功傳送機率的乘積。對於 RFID 系統內標籤與閱讀器來說,S=1 表示每個標籤的數據都被成功傳送給閱讀器,沒有發生標籤碰撞的情況;S=0 表示數據在傳送過程中發生了碰撞,閱讀器沒有接收到任何數據信息,也可能是無數據傳輸的情況。由此可以看出,在 RFID 系統中,系統的吞吐率與信道的利用率和標籤成功傳輸的機率成正比關係,與數據錯誤傳輸的機率成反比關係。
時隙 ALOHA 算法(SA)是在 PA 算法的基礎上考慮了時間因素,以此限制條件將其分成若干個具有一定時間間隔的時隙段的改進方法。在 PA 算法中,由於標籤選擇時間的隨機性,使得標籤的碰撞周期為 2T,標籤之間的碰撞還有部分碰撞的情況,所以為了減少碰撞周期,避免部分碰撞情況的發生,SA 算法由此應運而生。SA 算法增加了時隙的概念,將傳輸時間離散化,標籤隨機的選擇某一時隙進行數據的傳送,如圖 2 所示。當標籤進入閱讀器的識別範圍後,標籤自身攜帶的隨機數發生器產生一隨機數,標籤按此隨機數選擇時隙,若查詢時的時隙數與標籤選擇的時隙相匹配時標籤即回響,並立即傳送自身的數據信息;若時隙內有碰撞時,閱讀器將終止標籤繼續傳送信息並令標籤等待下一次查詢。在 SA 算法中,標籤只能選擇在每個時隙的開始階段傳送數據,而不是隨機的選擇時間傳送數據,所以需要一個同步機制來控制標籤,這個同步時鐘的控制由閱讀器來完成,並且每個時隙的長度要滿足標籤成功傳輸完一數據包所需的時間。圖2 時隙 ALOHA 算法碰撞原理圖
由圖2可以看出,在 SA 算法中,由於同步時鐘的控制,標籤只能在時隙開始的時間點傳送數據信息,並且標籤在單獨的每個時隙內進行數據傳輸,所以只有在同一時隙的同一時間點傳送數據的標籤才會發生碰撞,即標籤之間的碰撞只有完全碰撞,而沒有部分碰撞情況,所以標籤的衝突周期由 PA 算法的 2T 減少為 T。圖3 PA 和 SA 算法吞吐率與輸入負載的對比關係圖
SA 算法的系統效率為:
。
對上式求導後可得,當G=1時,S可取得最大值,
,比 PA 算法的吞吐率提高了一倍。圖3為利用 MATLAB 軟體對 PA 和 SA 算法進行仿真後,吞吐率與輸入負載的對比關係圖。
SA 算法雖然避免了部分碰撞情況的發生,提高了系統的識別效率,但是由於進行數據傳輸所需的時隙數是固定的,不能隨意進行動態調整,當標籤數量多時,時隙數不夠用,導致時隙內標籤的碰撞率急劇上升,也急劇的降低了系統的識別效率和信道利用率;當標籤數量少時,如有的時隙內沒有標籤在傳輸數據,則會產生許多空時隙,造成時隙的浪費。

 圖1 純 ALOHA 算法碰撞原理示意圖
圖1 純 ALOHA 算法碰撞原理示意圖 圖2 時隙 ALOHA 算法碰撞原理圖
圖2 時隙 ALOHA 算法碰撞原理圖 圖3 PA 和 SA 算法吞吐率與輸入負載的對比關係圖
圖3 PA 和 SA 算法吞吐率與輸入負載的對比關係圖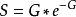 。
。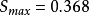 ,比 PA 算法的吞吐率提高了一倍。圖3為利用 MATLAB 軟體對 PA 和 SA 算法進行仿真後,吞吐率與輸入負載的對比關係圖。
,比 PA 算法的吞吐率提高了一倍。圖3為利用 MATLAB 軟體對 PA 和 SA 算法進行仿真後,吞吐率與輸入負載的對比關係圖。 (時隙的個數);
(時隙的個數); ,空時隙數量
,空時隙數量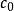 和成功時隙數量
和成功時隙數量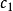 ),採用一定的標籤估算方法來估算場區內的標籤數量 n,並且據此選擇一個合適的幀長度
),採用一定的標籤估算方法來估算場區內的標籤數量 n,並且據此選擇一個合適的幀長度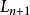 ;
;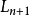 為下一輪識別的幀長,直到讀寫器工作場區內的標籤被全部識別完畢。
為下一輪識別的幀長,直到讀寫器工作場區內的標籤被全部識別完畢。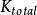 ,各個傳送方在碼集中競爭碼字傳送分組,則稱為基於接收方的擴頻傳輸協定(R-SSA),它的特點是可以節省碼字數,減少碼字的同步時間,但有可能出現碼字競爭衝突。在MC-S-ALOHA中,假設有N個窄帶時隙ALOHA並行正交子信道,這些子信道的頻寬之和等於CDMA系統的頻寬。忽略熱噪聲的影響及載波間的干擾,則可以在時隙ALOHA方案中不採用糾錯編碼。
,各個傳送方在碼集中競爭碼字傳送分組,則稱為基於接收方的擴頻傳輸協定(R-SSA),它的特點是可以節省碼字數,減少碼字的同步時間,但有可能出現碼字競爭衝突。在MC-S-ALOHA中,假設有N個窄帶時隙ALOHA並行正交子信道,這些子信道的頻寬之和等於CDMA系統的頻寬。忽略熱噪聲的影響及載波間的干擾,則可以在時隙ALOHA方案中不採用糾錯編碼。