基本介紹
- 中文名:差分隱私
- 外文名:Differential privacy
- 領域:密碼學
正式的定義和套用示例,靈敏度,準確性與隱私的均衡,差分隱私的其他概念,差分隱私機制,拉普拉斯機制,Netflix獎,醫療資料庫事件,元數據與流動資料庫,現實世界中對差分隱私的採用,
正式的定義和套用示例
假設 是一個正實數,A是一個隨機算法,它將數據集作為輸入(表示信任方擁有的數據)。imA表示A的映射。對於在非單個元素(即,一個人的數據)的所有數據集D1和D2以及imA的所有子集S,算法A是
是一個正實數,A是一個隨機算法,它將數據集作為輸入(表示信任方擁有的數據)。imA表示A的映射。對於在非單個元素(即,一個人的數據)的所有數據集D1和D2以及imA的所有子集S,算法A是  -差分隱私,其中機率取決於算法的隨機性。
-差分隱私,其中機率取決於算法的隨機性。
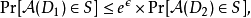
例如, 假設我們有一個醫療記錄資料庫 D1 在那裡每條記錄是一對 (名字, x), 其中 X 是一個布爾值表示一個人是否瘓有糖尿病。例如:
姓名 | 有糖尿病 |
Ross | 是1 |
Monica | 是1 |
Joey | 否0 |
Phoebe | 否0 |
Chandler | 是1 |
現在假設一個惡意用戶 (通常被稱為攻擊者) 想知道Chandler是否有糖尿病。假設他知道Chandler在資料庫的哪一行。現在攻擊者只能使用特定形式的查詢Qi返回資料庫中前i行中第一列 X 的部分總和。攻擊者為了獲取Chandler是否有糖尿病的信息。只需要執行兩個查詢 Q5(D1)和Q4(D1),分別計算前五行和前四行的總和,然後計算兩個查詢的差別。在本例中Q5(D1)=3,Q4(D1)=2,差是1。攻擊者在知道Chandler在第5行的情況下,就會知道他的糖尿病狀況是1(有糖尿病)。這個例子顯示了即使在沒有明確查詢特定個人信息的情況下, 個人信息如何被泄露。
繼續這個例子,如果我們用(Chandler,0)代替(Chandler,1)構造D2,那么這個惡意攻擊者將能夠通過計算每個數據集的Q5-Q4來區分D2和D1。 如果攻擊者被要求通過 -差分隱私算法接收Qi值,對於足夠小的
-差分隱私算法接收Qi值,對於足夠小的 ,則他將不能區分這兩個數據集。
,則他將不能區分這兩個數據集。
靈敏度
d為正整數,D為一個數據集的集合,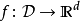 為函式。
為函式。 代表的函式的靈敏度由下式定義:
代表的函式的靈敏度由下式定義:
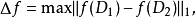
其中最大值是D中的所有對數據集對應的D1和D2中最差別最大的一對,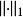 表示曼哈頓距離。
表示曼哈頓距離。
在上面醫學資料庫的例子中,如果我們認為f是函式Qi,那么函式的靈敏度就是1,因為改變資料庫中的任何一個條目都會導致函式的輸出改變0或 1。
有一些技術(如下所述),我們可以使用這些技術建立低靈敏度差分隱私算法。
準確性與隱私的均衡
通過差分隱私加擾的結果,要在統計數據的準確性和隱私參數之間有權衡.這種均衡也必須考慮到ε參數乘以查詢數量(包括預計的查詢數量)。
差分隱私的其他概念
對很多套用而言, 差分隱私被認為過於嚴格, 因此建議了許多被弱化的版本。這些包括 (ε, δ)-差分隱私, 隨機差分隱私, 以及特定標度的隱私。
差分隱私機制
由於差分隱私是一個機率概念,任何差分隱私機制必然是隨機的。 下面描述的拉普拉斯機制就依賴於我們對結果添加的受控噪聲。 其他的像指數機制和後驗抽樣依賴於問題的分布族。
拉普拉斯機制
許多差分隱私方法以添加受控噪音實現降低查詢結果的靈敏度。拉普拉斯機制增加了拉普拉斯噪聲(即符合拉普拉斯分布的噪聲,其可以用機率密度函式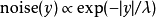 表示,其均值為0和標準偏差是
表示,其均值為0和標準偏差是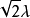 )。 現在在我們的例子中,我們將的輸出函式定義為實值函式(稱為
)。 現在在我們的例子中,我們將的輸出函式定義為實值函式(稱為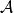 的輸出副本)為
的輸出副本)為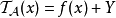 ,其中
,其中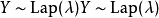 和f是我們計畫在資料庫上執行的原始實值查詢/函式。現在很明顯,
和f是我們計畫在資料庫上執行的原始實值查詢/函式。現在很明顯,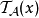 可以被認為是一個連續的隨機變數,其中
可以被認為是一個連續的隨機變數,其中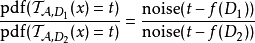 ,最多為
,最多為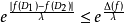 .我們可以認為是隱私因子
.我們可以認為是隱私因子 .
.
因此,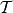 遵循不同的隱私機制(從上面的定義可以看出)。 如果我們試圖在我們的糖尿病例子中使用這個概念,那么從上面推導出的事實可以看出,為了讓
遵循不同的隱私機制(從上面的定義可以看出)。 如果我們試圖在我們的糖尿病例子中使用這個概念,那么從上面推導出的事實可以看出,為了讓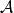 作為
作為 -差分隱私算法,我們需要
-差分隱私算法,我們需要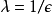 。 雖然我們在這裡使用了拉普拉斯噪聲,但也可以使用其他形式的噪聲,例如高斯噪聲,但這樣可能需要略微放寬差分隱私的定義。
。 雖然我們在這裡使用了拉普拉斯噪聲,但也可以使用其他形式的噪聲,例如高斯噪聲,但這樣可能需要略微放寬差分隱私的定義。
構想一個受信任的機構持有涉及眾多人的敏感個人信息(例如醫療記錄、觀看記錄或電子郵件統計)的數據集,但想提供一個全局性的統計數據。這樣的系統被稱為統計資料庫。但是,提供有關數據的綜合性統計也可能揭示一些涉及個人的信息。事實上,當研究人員連結兩個或多個分別無害化處理的資料庫來識別個人信息時,各種公共記錄匿名化的特殊方法都失效了。而差分隱私就是為防護這類統計資料庫脫匿名技術而形成的一個隱私框架。
Netflix獎
舉例來說,2006年10月,Netflix提出一筆100萬美元的獎金,作為將其推薦系統改進達10%的獎勵。Netflix還發布了一個訓練數據集供競選開發者訓練其系統。在發布此數據集時,Netflix提供了免責聲明:為保護客戶的隱私,可識別單個客戶的所有個人信息已被刪除,並且所有客戶ID已用隨機分配的ID [sic]替代。
Netflix不是網路上唯一的電影評級入口網站,其他網站還有很多,包括IMDb。個人可以在IMDb上註冊和評價電影,並且可以選擇匿名化自己的詳情。德克薩斯州大學奧斯汀分校的研究員Arvind Narayanan和Vitaly Shmatikov將Netflix匿名化的訓練資料庫與IMDb資料庫(根據用戶評價日期)相連,能夠部分反匿名化Netflix的訓練資料庫,危及到部分用戶的身份信息。
醫療資料庫事件
元數據與流動資料庫
MIT的De Montjoye等人引入了單一性(意為獨特性)概念,顯示出4個時空點、近似地點和時間就足以唯一性識別一個150萬人流動資料庫中的95%用戶。該研究進一步表明,即使數據集的解析度較低,這些約束仍然存在,即粗糙或模糊的流動數據集和元數據也只提供很少的匿名性。
現實世界中對差分隱私的採用
至今為止,比較知名的採用差分隱私的套用如下:
- 美國人口普查局,展示通勤模式。
- Google的RAPPOR,用於遙測,例如了解統計劫持用戶設定的惡意軟體。
- Google,分享歷史流量統計信息。
- 在數據挖掘模型中使用差異隱私的實際表現已有一些初步研究。
