
基本介紹
- 中文名:Word2vec
- 外文名:word to vector
- 領域:深度學習
- 定義:用來產生詞向量的相關模型
- 依賴:skip-grams或連續詞袋
- 套用:自然語言處理
簡介,依賴,套用,有關術語,
簡介
隨著計算機套用領域的不斷擴大,自然語言處理受到了人們的高度重視。機器翻譯、語音識別以及信息檢索等套用需求對計算機的自然語言處理能力提出了越來越高的要求。為了使計算機能夠處理自然語言,首先需要對自然語言進行建模。自然語言建模方法經歷了從基於規則的方法到基於統計方法的轉變。從基於統計的建模方法得到的自然語言模型稱為統計語言模型。有許多統計語言建模技術,包括n-gram、神經網路以及 log_linear 模型等。在對自然語言進行建模的過程中,會出現維數災難、詞語相似性、模型泛化能力以及模型性能等問題。尋找上述問題的解決方案是推動統計語言模型不斷發展的內在動力。在對統計語言模型進行研究的背景下,Google 公司在 2013年開放了 Word2vec這一款用於訓練詞向量的軟體工具。Word2vec 可以根據給定的語料庫,通過最佳化後的訓練模型快速有效地將一個詞語表達成向量形式,為自然語言處理領域的套用研究提供了新的工具。Word2vec依賴skip-grams或連續詞袋(CBOW)來建立神經詞嵌入。Word2vec為托馬斯·米科洛夫(Tomas Mikolov)在Google帶領的研究團隊創造。該算法漸漸被其他人所分析和解釋。
依賴
詞袋模型
詞袋模型(Bag-of-words model)是個在自然語言處理和信息檢索(IR)下被簡化的表達模型。此模型下,像是句子或是檔案這樣的文字可以用一個袋子裝著這些詞的方式表現,這種表現方式不考慮文法以及詞的順序。最近詞袋模型也被套用在計算機視覺領域。詞袋模型被廣泛套用在檔案分類,詞出現的頻率可以用來當作訓練分類器的特徵。關於"詞袋"這個用字的由來可追溯到澤里格·哈里斯於1954年在Distributional Structure的文章。
Skip-gram 模型
Skip-gram 模型是一個簡單但卻非常實用的模型。在自然語言處理中,語料的選取是一個相當重要的問題: 第一,語料必須充分。一方面詞典的詞量要足夠大,另一方面要儘可能多地包含反映詞語之間關係的句子,例如,只有“魚在水中游”這種句式在語料中儘可能地多,模型才能夠學習到該句中的語義和語法關係,這和人類學習自然語言一個道理,重複的次數多了,也就會模仿了; 第二,語料必須準確。 也就是說所選取的語料能夠正確反映該語言的語義和語法關係,這一點似乎不難做到,例如中文裡,《人民日報》的語料比較準確。 但是,更多的時候,並不是語料的選取引發了對準確性問題的擔憂,而是處理的方法。 n元模型中,因為視窗大小的限制,導致超出視窗範圍的詞語與當前詞之間的關係不能被正確地反映到模型之中,如果單純擴大視窗大小又會增加訓練的複雜度。Skip-gram 模型的提出很好地解決了這些問題。顧名思義,Skip-gram 就是“跳過某些符號”,例如,句子“中國足球踢得真是太爛了”有4個3元詞組,分別是“中國足球踢得”、“足球踢得真是”、“踢得真是太爛”、“真是太爛了”,可是我們發現,這個句子的本意就是“中國足球太爛”可是上述 4個3元詞組並不能反映出這個信息。Skip-gram 模型卻允許某些詞被跳過,因此可以組成“中國足球太爛”這個3元詞組。 如果允許跳過2個詞,即 2-Skip-gram。
套用
Word2vec用來建構整份檔案(而非獨立的詞)的延伸套用已被提出,該延伸稱為paragraph2vec或doc2vec,並且用C、Python和 Java/Scala實做成工具。Java和Python也支援推斷檔案嵌入於未觀測的檔案。對word2vec框架為何做詞嵌入如此成功知之甚少,約阿夫·哥德堡(Yoav Goldberg)和歐莫·列維(Omer Levy)指出word2vec的功能導致相似文本擁有相似的嵌入(用餘弦相似性計算)並且和約翰·魯伯特·弗斯的分布假說有關。詞嵌入是自然語言處理(NLP)中語言模型與表征學習技術的統稱。概念上而言,它是指把一個維數為所有詞的數量的高維空間嵌入到一個維數低得多的連續向量空間中,每個單詞或詞組被映射為實數域上的向量。詞嵌入的方法包括人工神經網路、對詞語同現矩陣降維、機率模型以及單詞所在上下文的顯式表示等。在底層輸入中,使用詞嵌入來表示詞組的方法極大提升了NLP中語法分析器和文本情感分析等的效果。詞嵌入技術起源於2000年。約書亞·本希奧等人在一系列論文中使用了神經機率語言模型(Neural probabilistic language models)使機器“習得詞語的分散式表示(learning a distributed representation for words)”,從而達到將詞語空間降維的目的。羅維斯(Roweis)與索爾(Saul)在《科學》上發表了用局部線性嵌入(LLE)來學習高維數據結構的低維表示方法。這個領域開始時穩步發展,在2010年後突飛猛進;一定程度上而言,這是因為這段時間裡向量的質量與模型的訓練速度有極大的突破。詞嵌入領域的分支繁多,有許多學者致力於其研究。2013年,谷歌一個托馬斯·米科洛維(Tomas Mikolov)領導的團隊發明了一套工具word2vec來進行詞嵌入,訓練向量空間模型的速度比以往的方法都快。許多新興的詞嵌入基於人工神經網路,而不是過去的n元語法模型和非監督式學習。
有關術語
統計語言模型
統計語言模型是用於刻畫一個句子出現機率的模型。給定一個由 n 個詞語按順序組成的句子 ,則機率
,則機率 即為統計語言模型。通過貝葉斯公式,可以將機率
即為統計語言模型。通過貝葉斯公式,可以將機率 進行分解。要計算一個句子出現的機率,只需要計算出在給定上下文的情況下,下一個詞為某個詞的機率即可,即
進行分解。要計算一個句子出現的機率,只需要計算出在給定上下文的情況下,下一個詞為某個詞的機率即可,即  。當所有條件機率都計算出來後,通過連乘即可計算出
。當所有條件機率都計算出來後,通過連乘即可計算出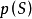 。所以,統計語言模型的關鍵問題在於找到計算條件機率 的模型。
。所以,統計語言模型的關鍵問題在於找到計算條件機率 的模型。
詞向量
詞向量具有良好的語義特性,是表示詞語特徵的常用方式。詞向量每一維的值代表一個具有一定的語義和語法上解釋的特徵。所以,可以將詞向量的每一維稱為一個詞語特徵。詞向量具有多種形式,distributed representation 是其中一種。一個 distributed representation 是一個稠密、低維的實值向量。distributed representation 的每一維表示詞語的一個潛在特徵,該特 征捕獲了有用的句法和語義特性。可見 ,distributed representation 中的 distributed 一詞體現了詞向量這樣一個特點:將詞語的不同句法和語義特徵分布到它的每一個維度去表示。
