
SimRank 是一種基於圖的拓撲結構信息來衡量任意兩個對象間相似程度的模型,該模型由 MIT 實驗室的 Glen Jeh 和 Jennifer Widom教授在2002年首先提出。[1]SimRank相似度的核心思想為:如果兩個對象和被其相似的對象所引用(即它們有相似的入鄰邊結構),那么這兩個對象也相似。近年來已在信息檢索領域引起廣泛關注,成功套用於網頁排名、協同過濾、孤立點檢測、網路圖聚類、近似查詢處理等。
原理,矩陣形式,實現,套用,
原理
結構相似度(Structural Similarity)是一種通過網路圖的拓撲結構信息(如網頁連結關係)來衡量對象間相似程度的普適模型。SimRank是一種基於網頁連結結構來評估圖中任意兩個對象(結點)之間的相似度模型。
SimRank 模型定義兩個頁面的相似度是基於下面的遞歸思想:如果指向結點 和指向結點
和指向結點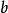 的結點相似,那么和也認為是相似的。這個遞歸定義的初始條件是:每個結點與它自身最相似。如果用記號
的結點相似,那么和也認為是相似的。這個遞歸定義的初始條件是:每個結點與它自身最相似。如果用記號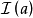 表示所有指向結點的結點集合(即入鄰點集合),用
表示所有指向結點的結點集合(即入鄰點集合),用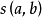 表示兩個對象間的SimRank相似度,則SimRank的數學定義式可以表示如下:
表示兩個對象間的SimRank相似度,則SimRank的數學定義式可以表示如下:
(1)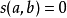 ,當
,當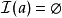 或
或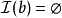 ;
;
(2) 在其它情況下,
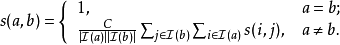
其中,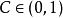 是一個阻尼係數(decay factor),通常取0.6-0.8。
是一個阻尼係數(decay factor),通常取0.6-0.8。
矩陣形式
假設:

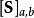
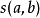
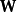
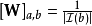
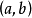
於是,SimRank方程式可以用矩陣的形式表示如下:
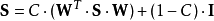
其中,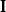 是一個單位矩陣。
是一個單位矩陣。
實現
由於 SimRank 相似度是通過遞歸定義的,因此它依賴於圖中其他結點對的相似度。現有的 SimRank 相似度計算方法主要分兩大類:
(1)SimRank 確定性計算
這類方法主要基於不動點疊代來求解 SimRank 的值。對於一個網路圖 來說,傳統的直接疊代法計算所有結點對的相似度需要
來說,傳統的直接疊代法計算所有結點對的相似度需要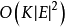 的時間複雜度和
的時間複雜度和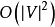 的記憶體,其中
的記憶體,其中 為總的疊代次數。文獻和計算所有結點對需要
為總的疊代次數。文獻和計算所有結點對需要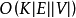 的時間複雜度。
的時間複雜度。
(2)SimRank 隨機算法
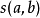
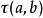

這種方法的計算每一個結點對的時間和記憶體複雜度均為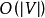 ,其精度由機率估計。
,其精度由機率估計。
套用
SimRank套用於網頁排名、協同過濾、孤立點檢測、網路圖聚類、近似查詢處理等。
